








在开发过程中,经常会依赖各种库,可能是公共的、可能是公司内部的。这些依赖给我们开发带来了很多便利,避免了重复造轮子。但是这也导致程序中的很多部分彻底变成了黑盒,出现问题时更加难以定位和确定根因,使得很多时候既没有明确的排查方向,又要面对程序执行的黑盒,根本无从下手。
常常会遇到通过日志发现底层依赖库抛出了异常,例如依赖的某个库中抛出了网路连接的错误,通过日志看到产生了Connection Refused或者响应发生了超时,但通过 APM 工具发现网络和其他依赖服务都没有问题,只能看着错误信息干着急。

要不先求助依赖库的开发同学看看
再求助负责基础设施的同事帮帮忙
最后只能重新想办法,可办法又是什么呢?

通过查看日志,我们定位到抛出异常的库。但是,我们并没有对这个库进行过任何变更,那么该如何进行接下来的排查呢?又需要哪些数据来佐证内心对问题的各种推测和猜想呢?这些推测和猜想又真的是正确的方向么?

需要明确方向,打开盲区
一方面需要对 Trace 数据做更加深入和全面的分析及数据关联来明确排查方向,另一方面需要真正能够彻底消除盲区,真实还原程序执行过程。
Kindling-OriginX 通过分析和关联 Trace 、Log、Metrics 数据,补充并细化 trace-profiling 的指标,深入并明确问题方向;另一方面利用 eBPF 结合 trace-profiling 技术打开程序执行和系统调用盲区,从根本上彻底还原程序执行过程,不再有黑盒存在。

定位关键指标,关联相关数据
依赖的相关代码中确实存在bug。




智能化给出可解释性的根因报告
根据报告和数据发现网络设施确实存在波动,提供相关交接数据。


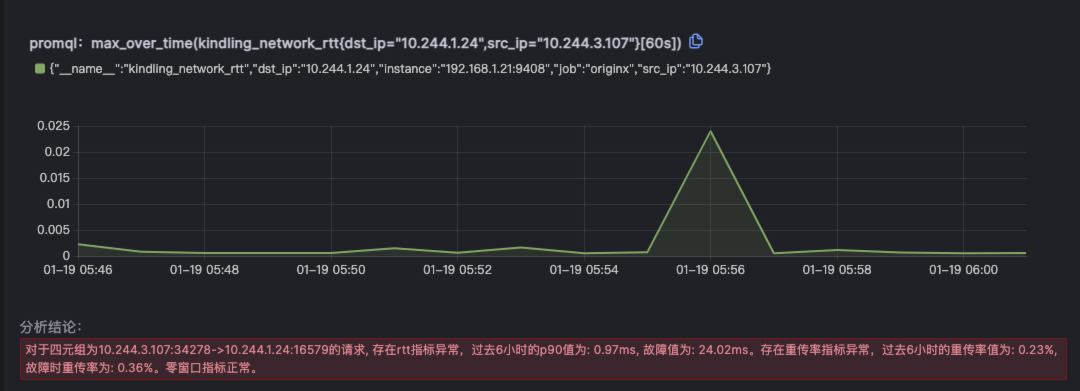

自动化Tracing关联分析异常数据,彻底打开全部盲区
消除传统 Trace、Log、Metrics 数据中的盲区,找到盲区中的问题点,发现存在DNS耗时异常。





对于难以明确排查方向,无法定界的故障,Kindling-OriginX 快速组织和分析故障线索,通过自动化 Tracing 关联分析,以给出可解释的根因报告的方式,为这类故障提供可操作的排查方法。