








选自Distill,作者:Alexander Mordvintsev等,机器之心编译。
近日,期刊平台 Distill 发布了谷歌研究人员的一篇文章,介绍一个适用于神经网络可视化和风格迁移的强大工具:可微图像参数化。这篇文章从多个方面介绍了该工具,机器之心选取部分内容进行了编译介绍。
图像分类神经网络拥有卓越的图像生成能力。DeepDream [1]、风格迁移 [2] 和特征可视化 [3] 等技术利用这种能力作为探索神经网络内部原理的强大工具,并基于神经网络把艺术创作推进了一小步。
所有这些技术基本上以相同的方式工作。计算机视觉领域使用的神经网络拥有图像的丰富内部表征。我们可以使用该表征描述我们希望图像具备的特性(如风格),然后优化图像使其具备这些特性。这种优化是可能的,因为网络对于输入是可微的:我们可以轻微调整图像以更好地拟合期望特性,然后迭代地在梯度下降中应用这种微调。
通常,我们将输入图像参数化为每个像素的 RGB 值,但这不是唯一的方式。由于从参数到图像的映射是可微的,我们仍然可以用梯度下降来优化可替代的参数设定。

图 1:当图像参数化可微的时候,我们就可以对其使用反向传播(橙色箭头)来优化。
为什么参数化很重要?
这可能令人惊讶,即改变优化问题的参数设定可以如此显著地改变结果,尽管实际被优化的目标函数仍然是相同的形式。为什么参数设定的选择有如此显著的效果?原因如下:
(1)改善优化:转换输入使优化问题更简单,这是一种被称为「预处理」的技术,是优化过程的重要部分。我们发现参数设定的简单变化就可以使图像优化变得更加简单。
(2)引力盆地:当我们优化神经网络的输入时,通常有很多不同的解,对应不同的局部极小值。优化过程落入某个局部极小值是由其引力盆地(即在极小值影响下的优化曲面区域)控制的。改变优化问题的参数设定可以改变不同引力盆地的大小,影响可能的结果。
(3)附加约束:某些参数设定仅覆盖可能输入的子集,而不是整个空间。在这种参数设定下的优化器仍然寻找最小化或最大化目标函数的解,但它们需要服从参数设定的约束。通过选择正确的约束集,我们可以施加多种约束,从简单的约束(例如,图像边界必须是黑色的)到复杂而精细的约束。
(4)暗含地优化其它目标函数:参数化可能内在地使用一种和输出不同的目标函数,并对其进行优化。例如,当视觉网络的输入是一张 RGB 图像时,我们可以参数化那张图像为一个 3D 物体渲染图,并在渲染过程中使用反向传播以进行优化。由于 3D 物体比图像具有更多的自由度,我们通常使用随机参数化,它能生成从不同视角渲染的图像。
在文章接下来的部分中,我们将给出几个示例,证明使用上述方法的有效性,它们带来了令人惊讶和有趣的视觉结果。
对齐特征可视化解释
相关 colab 页面:https://colab.research.google.com/github/tensorflow/lucid/blob/master/notebooks/differentiable-parameterizations/aligned_interpolation.ipynb
特征可视化最常用于可视化单个神经元,但它也可用来可视化神经元组合,以研究它们如何相互作用 [3]。这时不是优化一张图像来激活单个神经元,而是优化它来激活多个神经元。
当我们希望真正地理解两个神经元之间的相互作用时,我们可以更进一步并创建多个可视化,逐渐把目标函数从优化一个神经元转移到给另一个激活神经元赋予更多的权重。这在某种程度上和生成模型(如 GAN)的潜在空间插值相似。
尽管如此,仍然存在一些小问题:特征可视化是随机的。即使你优化的是同一个物体,其每一次的可视化图也是不同的。一般而言,这不是什么问题,但它确实阻碍了插值可视化。如果就这样处理,得到的可视化将是非对齐的:视觉关键点(例如眼睛)将出现在每张图像的不同位置。在稍微不同的物体中,缺乏对齐将更难识别差异,因为差异被更明显的图式差异掩盖了。
如果我们观察插值帧的动画演示,就可以看到独立优化存在的问题:
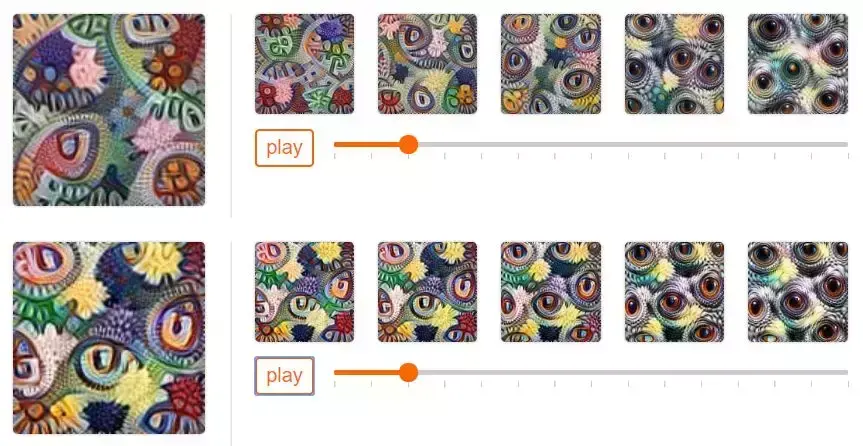
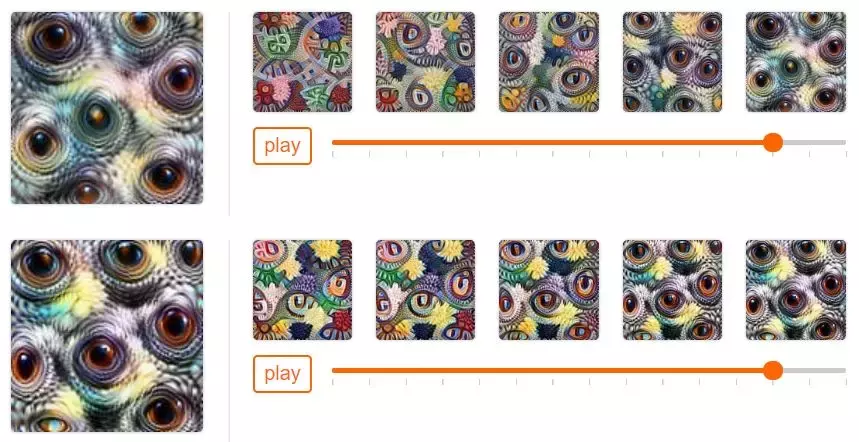
图 2:(1、3 行)非对齐插值:视觉关键点(例如眼睛)从一帧到下一帧的位置会改变。(2、4 行)不同的帧更容易比较,因为视觉关键点在相同位置。
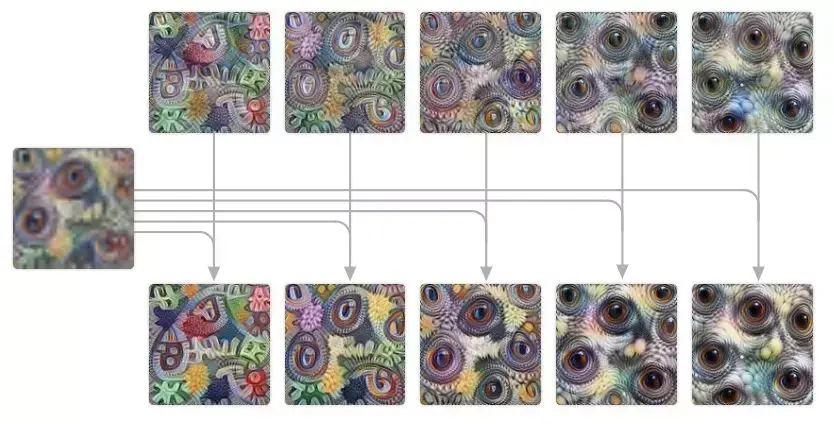
图 3:(顶行)从独立参数化的帧开始;(中行)然后每个帧结合单个共享参数设定;(底行)创建一个视觉对齐的神经元插值。
通过在帧之间部分共享一个参数设定,我们促进可视化结果自然地对齐。直觉上,共享参数设定提供了视觉关键点位移的一个共同参照,但是单独的参数设定基于插值权重赋予每个帧自己的视觉效果。这种参数设定并没有改变目标函数,但确实放大了引力盆地(其中可视化是对齐的)。
这是可微参数化在可视化神经网络中作为有用辅助工具的第一个示例。
通过 3D 渲染进行纹理风格迁移
相关 colab 页面:https://colab.research.google.com/github/tensorflow/lucid/blob/master/notebooks/differentiable-parameterizations/style_transfer_3d.ipynb
现在我们已经构造了一个高效反向传播到 UV 映射纹理的框架,该框架可用于调整现有风格迁移技术来适应 3D 物体。与 2D 情况类似,我们的目标是用用户提供图像的风格进行原始物体纹理的再绘制。下图是该方法的概述:
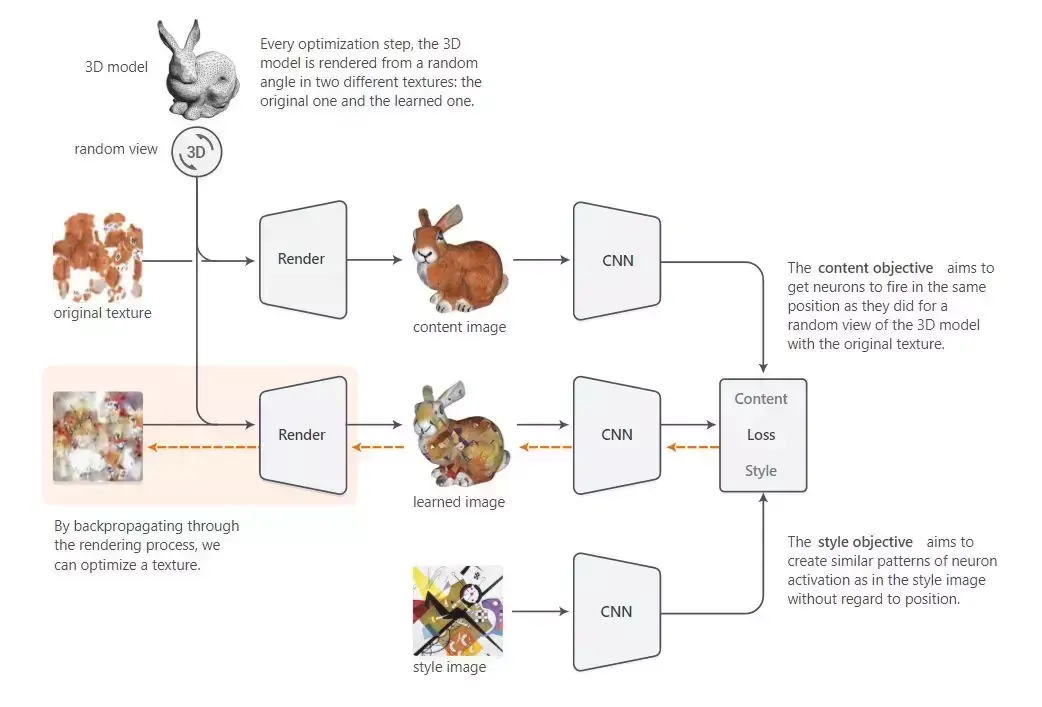
该算法开始于随机初始化纹理。在每次迭代中,我们采样出一个指向物体边界框中心的随机视点,并渲染它的两个图像:一个是有原始纹理的内容图像(content image),另一个是有当前优化纹理的学习图像(learned image)。
在对内容图像和学习图像进行渲染后,我们对 Gatys 等人 [2] 的风格迁移目标函数进行了优化,并将参数化映射回 UV 映射纹理中。重复该过程,直到在目标纹理中实现期望的内容与风格融合。


图 17:各类 3D 模型的风格迁移。注意:内容纹理中的视觉关键点(如眼睛)在生成纹理中正确地显示出来。
因为每个视图都是独立优化的,所以在每次迭代中优化都要把该风格的所有元素融合进去。例如,如果选择梵高的《星夜》作为风格图像,那每个单视图都会加上星星。我们发现,引入先前视图风格的「记忆」会获得更好的结果,如上图所示。为此,我们在近期采样视点上维持表征风格的 Gram 矩阵的滑动平均不变。在每次优化迭代时,我们根据平均矩阵来计算风格损失,而不是基于特定视图计算。
最终纹理结合了期望风格的元素,同时保持了原始纹理的特征。譬如将梵高的《星夜》作为风格图像的模型,其最终纹理就包含了梵高作品中轻快有力的笔触风格。然而,尽管风格图像是冷色调的,最终照片里的皮毛还是保持了原始纹理的暖橙色调。更有趣的是风格迁移时兔子眼睛的处理方式。例如,当风格来自梵高的画作,那兔子的眼睛会像星星一样旋转,而如果是康定斯基的作品,兔子眼睛就会变成抽象图案,但仍然类似原始眼睛。

图 18:将立体派画家费尔南·莱热的画作 The large one parades on red bottom (Fernand Leger, 1953) 的风格迁移到 Stanford Bunny(Greg Turk & Marc Levoy)上的 3D 打印结果。
结论
对于充满创造力的艺术家或研究者来说,对参数化图像进行优化还有很大的空间。这不仅生成了截然不同的图像结果,还可以生成动画和 3D 图像。我们认为本文探讨的可能性只触及了皮毛。例如,你可以将对 3D 物体纹理进行优化扩展到对材料或反射率的优化,甚至可以沿着 Kato 等人 [15] 的方向,继续优化 mesh 顶点位置。
本文主要讨论了可微图像参数化,因为它们易于优化且涵盖了大多应用程序。当然,通过强化学习或进化策略 [17, 18] 来优化不可微或部分可微的图像参数化也是能够实现的。使用不可微参数化实现图像或场景生成也很令人期待。