








据产业分析师预测,2019年苹果AirPods出货量将超过5000亿台,2021年更是有望破亿!这款从发布被人嘲笑,到后来成功引领市场的产品,早已成为各家追赶超越的对象。耳机行业近几十年来没有发生重大变革,TWS耳机的出现让整个市场未来将有数百亿美元的成长空间。
AirPods已经成为苹果增长最快的配件产品,在手机销量整体滑坡的现在,每一个手机厂商都在找自己的突破点,如何重新占领市场先机成为了尤为重要的关键。

AirPods这种TWS耳机不仅使音频市场重获生机,也成为了苹果这样的手机厂商的救命稻草,由AirPods引出的:语音交互、骨声纹识别支付、加入eSIM独立使用等已成为TWS耳机下一个战场。
TWS耳机被称之为2019消费电子市场最大亮点,智能语音识别的加入将TWS耳机市场蛋糕持续扩大,更是吸引了五大玩家入局:
运营商入局:联通、移动,让耳机产品独立使用成为可能;
互联网巨头抢占入口:亚马逊、谷歌、微软、百度;
电商与支付加入:微信、支付宝,骨声纹识别、安全支付,由手机支付到骨声纹支付的变革。
手机厂商持续加码:苹果、华为、小米、三星、索尼、OPPO、荣耀、一加、魅族,均已推出自家多款耳机产品。
内容平台紧跟其后:QQ音乐、网易音乐、喜马拉雅FM,为TWS耳机提供源源不断的生命力。
市场很久没有这么热闹,仿佛回到了智能手机爆发初期的繁荣阶段,接下来八仙过海,各取所需,各显神通。

上一轮的智能音箱争夺战中,我们看到以苹果、谷歌、亚马逊、百度、阿里、腾讯、小米等为代表的先头部队,这些巨头的加入,让中小企业只能选择站队,投靠到各自的阵营,以获取内容、流量、补贴等赖以生存的资源。
通过我爱音频网分析,智能耳机的风口比音箱将要来得更猛,更触手可及,今天我们一起来探讨如何抓住智能耳机的风口。
一、TWS耳机飞速发展,苹果靠Airpods领跑市场
IDC最近发布的2019年第一季度全球智能手机市场的调研报告。数据显示,全球智能手机出货量为 3.108 亿台,同比下降 6.6%。其中排在全球出货量前六位的厂商也大部分处于同比下降的状态,Apple甚至下降超过了 30%。
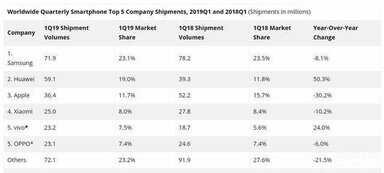
与手机市场的遇冷相比,TWS蓝牙耳机则是以一种不可思议的速度在发展。根据Counterpoint的数据显示,在2018年第四季度中,AirPods的出货量占到了市场的60%,达1250万台。
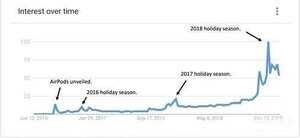
据Above Avalon报道,最近三年假日AirPods在谷歌上的峰值搜索兴趣,索引为100(代表最大搜索兴趣)。2016年的峰值为10,2017年为20,2018年为100,同比增长了500%,这样的增长速度实在令人吃惊。
由此可见TWS耳机的市场容量的巨大,音频和手机厂商也都纷纷加入这个领域,势必也要从这块巨大的蛋糕上狠狠切下一块。
而在2019年的3月20日,Apple推出全新的TWS真无线蓝牙耳机——Airpods2,这次升级,主控芯片换成了全新的H1,而功能上除了支持了无线充电之外,还有一个非常重要的一点,那就是语音唤醒。
二、TWS耳机语音唤醒方案实现的细节
Airpods的成功源于其优质的体验,而Airpods2代此次升级了语音唤醒,语音唤醒是智能语音非常重要的一环,手机上面早就大量支持比如iPhone的Hey Siri、小米9的小爱同学、samsung galaxy S10的Hi Bixby等等。

而在耳机端,大量的耳机依然使用的是触摸或者按键唤醒的方式来激活语音助手。物理触摸或者点按的方式与语音激活,两者体验的差距当然是不言而喻的。
Apple率先支持了语音唤醒,那么其他厂商是否能够跟上,又要如何实现。又有哪些技术细节需要去考量?
首先TWS 耳机本地唤醒词的应用由语音辨识及误唤醒处理 2 个部份组成:
1、唤醒词语音辩识(本地语音命令亦同)
唤醒词辩识需由前端信号处理把用户声音与背景声音的信噪比拉高以利在不同应用场景让唤醒词识得到最高唤醒率,我们列出从麦克风采集到用户的声音信息数据开始,至唤醒词识别结束。
依序完成唤醒词识别所需要的算法排列如下:
MIC→(LPSD 或 VAD)→(BF)→(NS 或 NR)→(KWD)
算法名称及参考供应商
LPSD 或 VAD, LPSD(Low Power Sound Detection), VAD(Voice Active Detection),参考供应商 DSPC,Seneory;
BF, BF(Beam Forming) 参考供应商 DSPC;
NS 或 NR, NS(Noise Suppression, Noise Reduction) 参考供应商 DSPC;
KWD, KWD(Key Word Detection) 参考供应商 Sensory, AI Speech, Nuance, Cyberon。
眼下市场上真正能提供出足够算力,使用单一蓝牙芯片就能集成上述算法并低功耗做到本地唤醒词功能的有高通的:QCC512x 及 QCC302x。
络达、瑞昱、恒玄等芯片产品建议搭配QuickLogic S3、Ambiq Apollo2、 Apollo3 或楼氏 IA-610、IA-611 智能麦克风芯片以达到在高算力低功耗要求下,满足本地唤醒词的功能。
所有的算法或芯片都必须以合法的方式取得使用权力及各种必要技术支持,这些供应商内 Quicklogic 的 EOS S3 是最早与宇恒互动 OVVP 算法做全面系统整合应用于实际客户产品上的,S3 芯片内部还带有 891 个可编程的Logic Cell,设计非常独特,可以满足特殊硬件接口的需要。
2、唤醒词或语音命令误唤醒误触发处理
误唤醒或误触发的定义:
TWS 耳机用户,非用户本人说出唤醒词或语音命令后,语音助手不回应或语音命令不动作,自己说出唤醒词后,却能唤醒或运行戴耳机用户的语音助手或语音命令。
市场上几个不同方案的说明:
2-1、基本处理
一般在唤醒词算法群内,BF 可以起到一定减低误唤醒率的作用,但与声源的方向有关,在双麦克风的间隔距离够远,产品结构声学架构调试恰当状况下 DSPC 的 BF 算法可以做到3db~6db。
这部份细节可以请教 DSPC 代理商聆感智能科技,他们有很专业的声学专家及实验室可以给需要的 TWS 耳机业者充分的声学相关设计服务。
2-2、使用 vpu 骨传导传感器
参考HUAWEI华为 FreeBuds2 Pro 应用 vpu(Voice Peak Up)。
vpu 严格说起来是使用一种 压电材料技术(因无法从datasheet内得知相关信息,只能从类似产品推论)的单轴加速度传感器(Voice Pick Up Sensor is a high performance accelerometer 引自Sonion Datasheet Description),主要是用来感测声带运动使用,是Sonion(声扬)公司的产品。

以-25dbv/g 这条输出强度线来看,最大带宽可以从 100hz 到 8khz 完整的含盖了人的声谱范围,整段频谱的响应并不平坦(特别是 3khz~5khz 刚好在人声的高频段),需要后段用加了高频负反馈的放大器整平。
这个传感器还有个优点就是低功耗(VDD=1.8V 时只要 55ua 电流),由于输出的是模拟信号,同时电平不足,拿来做 VAD 时若 A/D 采样的分辨率够,有机会可以不通过运放先做个 VAD 让传感器 Always On 感测到人声后才打开麦克风,这样可以达到降功耗的效果,但因 vpu 是模拟输出需要搭配芯片内的 A/D 转换器及算法,这还得看芯片的功耗换麦克风的功耗是不是划的来。
这类单轴骨传导传加速度感器在产品结构内的放置点,需要考虑用户使用过程中松脱后导致 vpu 输出声信息强度滑落的补偿问题。

HUAWEI华为 FreeBuds2 pro需要支持骨声纹支付,所以要较好的保证取到能做声纹辩识用的声音,在 vpu 保证不了足够的动态范围条件下,声带宽范围的放大器是免不了的,这样在功耗,器件数量及组装工艺,测试难度上都会有相当的增加。
加了高频负反馈放大器后拉升了低频加大了动态范围,同时也把人体运动低频信号又给拉了上来,vpu 自带天然的高通滤波效果又变差了,后面还又要加上高通滤波算法,过滤掉因人体运动引起传感器机械瞬态变化引发的多次谐波干扰,另外在通话,音乐应用场景下喇叭振动的串扰问题还得要处理解决。

所以从我爱音频网拆解的HUAWEI华为 FreeBuds2 pro 板上证实确实有运放,并且还加了个 DA14195 来处理各种算法及 A/D 的接口,这款产品使用唤醒词的感度大约 76db(在 OVVP 感度规格区间内)。
而唤醒词误唤醒处理可以达到19db~22db(在 OVVP 的语音强隔离护罩规格区间内)也是挺不错的,使用加速度骨传导传感器感测声带振动与只使用麦克风感测用户说话声音的差异是,在说唤醒词或语音命令时肯定,声量要大一些(差约 7db 左右),这大厂设计出来的产品还是很有代表性。

另外这个产品也有几条本地语音命令,科技感十足外还充分发挥了 vpu 的优势,跟苹果不同的是用户说话要稍微“大声一点”,但误唤醒处理又比苹果强很多,且没有声源方向限制,任何方向都可以。
但使用 vpu来感测用户说话声音,辅助完成安全度需求较高的支付功能,不知道无“清音”的语音声谱结构缺陷是不是比较严重的影响了用户体验。
使用骨传导传感器,未做清音补偿状况下会让,Recode 听成 code,Strange 听成 change,HUAWEI 听成 AWEI,,河听成了鹅,,福听成了无,钱听成了言。
声结构的改变会让人工智能语音识别产生严重错误,知乎上看到很多关于这方面的投诉,用户很刻意的大声说都没办法完成支付或声纹学习,似乎感觉这个问题解决的并不好,当然也可能 Freebuds2 pro 内的字词识别引擎处理的不好或某种不良所导致。

从产业角度看 HUAWEI 起了个好头领先苹果超过数月,将 TWS 耳机智能化脚步推快了几步,并在耳机产品数十年关注音质好坏,噪声水平之外,注入了智能语音应用的亮点与活水,教育了群众,活络了产业,让产业有了再扩张及引动新浪潮的可能。
2-3、使用 MEMS 加速度计骨传导传感器(上行降噪)
Apple Airpods,使用多重手段(LPSD、BF、骨导降噪)在背了“不改变用户使用习惯”的大锅条件下,唤醒词误唤醒处里约有 7db~9db 的效果(用户背后 0.5 米环境噪声 45db 与仅做 BF及 NS 处里的唤醒词开发板对比)。
AirPods支持唤醒词(本地,云端或本地+手机),所有的语音命令都在云端,在云端的优点是词汇的弹性无限,只要语义近似全都能用,识别精度更高,抗噪能力较强,占用本地芯片的资源较少,缺点是无法联网或联网品质不好时使用体验急速劣化甚至无法使用,响应速度较慢。

市场上能用于上行降噪的加速度传感器除了使用压电材料的 vpu(模拟输出)外,ST 意法半导体使用 MEMS 技术的LIS25BA(TDM 接口)是市场上唯一的产品,LIS25BA 是一个全数字产品,内含 A/D 及 TDM 接口,相关信息可以向 ST意法半导体索取。
虽然市场上有传感器可用,但受限于权利保护覆盖面强大严谨的苹果专利及担负改变上行声音数据声结构所造成风险的技术难度,眼下市场上还没有可流通的专用降噪算法,DSPC,Sensory,高通这些知名算法大拿都还没有明显动静,但一些国内 MEMS麦克风的厂家及一些国内算法公司已隐隐传出动静。
下面将对骨传导上行降噪算法的难度提出一些看法,因技术能力与知识范围有限,谬误之处还请包涵指教。这里简单的谈下骨传导与麦克风融合的上行降噪技术。
在进入主题前首先为大家介绍一篇来自肖新华先生在 2009 年提出的研究生毕业论文,让大家对后面提及的”TWS耳机语音算法技术难度”有个衡量基础:
《国防科学技术大学研究生院工程硕士学位论文:面向骨传导语音消噪算法及硬件实现技术研究》
这是一篇以非负稀疏编码 NNSC(Non-Negative Sparse Coding)为消噪核心主体并带上一个使用AMDF (Average Magnitude Difference Function)技术的 VAD 算法配合消除风噪,枪炮声,摩擦声。
这并非苹果公司使用的降噪技术,但可以让大家对骨传导降噪或 VAD 做个初步了解,这篇论文以人为可懂度衡量对象,用骨传导传感器感测的声带振动为主声源,一个传统麦克风做噪音拾取噪声源,通过算法完成降噪处里。
但现在可懂度的衡量对象除了人还有机器(语音识别算法),而机器对于可懂度的要求要比人高很多,因为机器对语音识别的整体智能还远不如人。
这里整理了一张对照表,以苹果的 TWS 耳机做为参照标准,比较使用 2 种完全不同性质的声传感器所感测到的声音信息数据在处理完降噪问题后要等于 1种声传感器所感测到的声音信息数据,将可能将要面临到多少问题及挑战。
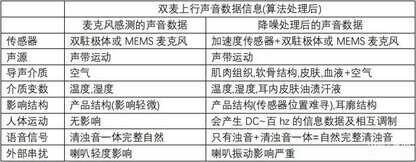
下面依据上表把问题做文字条列叙述式的整理:
1)双麦上行降噪算法技术的终极目标:只留下用户说话的声音,最大程度消去或压制,非用户
本人声带运动所发出的所有声音,但必须让降噪处理后的上行声音信息数据与使用传统麦克
风拾取到的用户原始说话声音信息数据完全相等。
2)算法使用了加速度骨传导传感,改变了过去由空气介质传导声能量,推动某种材料做成的
膜体转换成电能,改成了软骨肌肉皮肤介质来传导声音,但算法仍用到 2 个使用空气介质传导
的麦克风来补偿加速度骨传导传感器感测不到清音的缺陷,空气传导稳定度高变数少,并经多
年应用对其了解较为透彻,而通过软骨肌肉皮肤介质来传导声音,除了不稳定变数多另外相关
应用还在积垒过程,全球积垒最多应用经验的非苹果公司莫属。
3)下面我们列了几个算法需要完成的等式:
-1、加速度骨传导传感器+双麦克风=双麦克风
-2、(软骨肌肉皮肤汗液,油渍,粉尘介质传递变数)+空气温湿度介质传递变数=空气温湿
度介质传递变数
-3、单独浊音+(浊音+清音)=浊音+清音
-4、产品结构及耳廓结构严重影响+产品结构影响=产品结构影响
-5、人体运动严重影响+人体运动不影响=人体运动不影响
-6、人为算法融合拼接补偿 2 种不同材料,不同传导介质结构,不同响应相位严迟,低频调
制=严丝合缝混然一体
4)对于麦克风上行信息数据来说,这些是信息数据是用来听的,可存储的,可传递信息的,是具有广阔延申再应用的声音信息数据,并且需满足现存于市场上千百个声音应用软硬件的需求。
项目决策者必需慎之又慎,规划项目时慢 2 步决定,然后系统性的观察谨慎的测试为上。

苹果公司在 2012 年以前启动研发并于 2012 年 9 月 28 日提交 13/631,716 号专利,2014 年 4 月 3日提出WO 2014/051969 A1 专利,2016 年 9 月 8 日 Airpods 上市,2019 年 3 月 20 日 Airpods二代上市。
这么大的龙头企业漫漫 8年的岁月积垒,别小看这个技术,更何况现在国内市场上这些可能的算法供应者,都不可能具备苹果公司这样长期的积累,要实现弯道超车还有待观察。

从这里可以合理推测,苹果公司在 W1 或 H1 芯片内这个上行降噪技术可能是用到最大算力的程序,其中 H1 芯片估计还保留了一定的算力资源给未来做下行环境降噪用。
现在市场上的TWS 耳机蓝牙芯片产品,在低功耗的要求下,需要满足这个算法的算力需求,高通最高阶 QCC512x 的 DSP在次功耗的限制下,要实现也需要持续努力。
5)加速度骨传导传感器加入各种了机械瞬态变化及环境应力老化的物理特征,很多声应用信息技术与算法模型,需要更系统性的重新摸索探究,而其中因补偿清音及拼接融合2个不同传感器感测到的声音信息数据,导致声谐波组成的结构变化,对现存云端语音语义识别算法的可懂性能造成多大影响?需要仔细测试评估,人耳不易听出来的变化但对语音识别算法来说确可能致命。
6)在 Airpods 1代上市的过去几年裏 DSPC,Sensory 这些大咖算法供应商并没有下一步动作。这是一个有很大算法需求的高报酬市场,这些供应商的保持沉默,这背后原因值得去细思探讨。
7)算法需要解决相位失真,总谐波失真压制,信噪比保证,非用户语音的噪声判断转换压制比(纯浊音,纯清音),算法延迟,骨导声与麦克风声在不同情绪,音量条件下融合自适应或权重变化曲线,人体运动信息低频调制及多次谐波抑制,清浊音互换响应状态,降噪处理后的声谐波结构变化,耳机松脱后音量频响包络补偿。
8)算法要解决加速度骨传导传感器感测到的浊音声带运动与双麦克风在不同情绪,音量条件下所感测到的浊音+清音 2 个不同声音间的实时同步,重叠,拼接,融合处里所产生的谐波失真修补,平滑,滤波或压制。
9)上行降噪最重要的应用场景就是在通话场景,使用骨传导与麦克风融合降噪技术在大音量通话场景下就像把扩音器的麦克风贴在喇叭上,相移量足不足够可能引起严重的串扰,所以不能只盯在降噪上。
对于器件密度极高的 TWS 耳机来说,使用骨传导传感器来感测完整人声的应用,被自身加噪才是最大问题,同时还需要用麦克风声信息数据来补偿清音的声音缺陷信息数据。
在通话场景时关掉降噪算法或降低融合权重,做个伪骨传导降噪或者用户能拿到厂家给的有苹果50%降噪效果功能的算法产品,却需承担 100%的侵权风险可能!
喇叭造成的串扰图
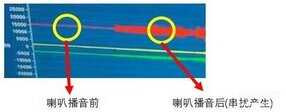
10)为稳定的取得最完整的用户声带运动信息数据,如何最佳化设计耳机结构,找寻加速度骨传导传感器所在的位置及适当使用导声材料,单轴的 vpu在位置,导声材料,产品结构,运动松脱,耳廓结构,生产工艺问题上影响远大于 3 轴的 LIS25BA,这是所以苹果用了 3 轴加速度计的可能原因。
11)利用不同人发出不同音量大小的/ s /,/ sh /,/ f /,/ he /……等纯清音,单由双麦克风检拾出来的声音,对比融合骨传导声音信息及麦克风声音信息降噪算法后的声音,验证融合算法自适应权重调整的处理效果,这里是一个两难的选择,因为清音处理的越好降噪效果就要打折,降噪效果越好清音就越听不清楚。
若因而导致唤醒词,语音命令或云端语音辩识服务器,手机语音输入法,翻译,语音转文字 APP 的辩识效果打了大折扣,在解决这个问题前,去使用到Amazon,Google, Microsoft,百度,阿里,腾讯,科大讯飞语音助手云端语音辩识的产品就要面临比较大的风险。
骨传导上行降噪在形成实际产品前有很多细微的研发生产测试支节参数需要仔细琢磨调试,耗时极长,大家可以从 iFixit 拆解 Airpods 从其内大量使用黏着剂固定,就能看出为了满足测试和维持性能指标,其组装工艺的巨大难度,一个带骨传导上行降噪的产品,在相关技术确定成熟了的条件下,从外观规划开始到出货花个 1 年估计算快的了,或许远远不够。
2-4、使用 ST LIS2DW12(SPI 接口)加速度计传感器+OVVP 算法(骨声纹用户说话识别)
传感器选型:OVVP 算法因为对噪声密度,分辨率,带宽,ODR 及传感器内部高低通滤波器有一定的限制及要求,眼下需指定搭配性价比最高的 ST LIS2DW12 传感器。
OVVP 算法与手机声纹识别比较说明:
这是我们客户曾经提过的一个代表性的问题,使用贵司的 OVVP 算法看起来跟使用手机 上的声纹识别效果类似,为何还要多此一举呢,下面我们做个对比 :
1)声纹识别需要针对特定字词做学习训练 OVVP 不用 ;
2)声纹识别只能对用户训练过的字词做局部保护,OVVP 则是对每个字词做全局性保护,
3)声纹识别的安全级别远高于 OVVP;
4)声纹识别易受用户环境,情绪,声哑病痛影响,OVVP 不会;
5)声纹识别只能对用户训练过的字词产生语音强隔离效果,OVVP 则对每个字词都能强隔离;
6)OVVP 算法是使用用户既有的加速度传感器与声纹识别一样不需外加硬件成本;
7)OVVP 算法可同时并存双击,计步,心率……等算法,声纹识别则无关;
8)声纹识别没有伴声记号,OVVP 的伴声记号可以用来做 2 次研发延展应用;
利用伴声记号与手机语音应用APP,强联结提升用户体验:
伴声记号是经由加速度传感器感测到用户说话时的声带运动,通过 OVVP 算法处理后,随着用户说话的字词产生的信息数据,最大的特征是只有戴耳机的用户“说话的时候”才会产生这个信息,戴耳机用户旁边的人说话声音小于语音强隔离护罩时,是无法产生这个信息数据的,我们客户产品语音强隔离护罩,能做到 50cm 100db 的程度。
伴声记号用法:
伴声记号(下图),是与麦克风声音数据一同通过蓝牙传送到手机端,通过 2 者同步后相互参照,可以知道用户何时说话及说了什么话。
翻译软件很多人用过,特别是谷歌翻译,相当好用, 翻译软件选择好翻译的语种后,说话前要先按下屏幕上的麦克风按键,然后说一句话,说完后停下等待翻成另一个语言,然后从手机喇叭播出,这个按下屏幕上的麦克风按键可以用伴声记号取代。
只要用户说话就自动压下屏幕上的麦克风按键,停止说话就翻译成另一个语言,通过喇叭播放出来,不用去按麦克风按键的翻译软件是不是更自然方便。
而带着伴声记号的用户说话声可以让语音辩识算法,除了肯定是近场拾取到用户自己说话的声音之外,快速得到声音的起点,停点这 3 个重要信息可以有效优化语音识别算法的应用体验。
这类语音应用软件除了翻译软件外还有很多,如,微信语音短信息,录音机,语音输入法,语音助手,语言学习,手机驾驶模式,语音转文字……等。
而与伴声记号同时存在的声音强隔离护罩,更是让用户在多人高密度及较吵杂环境,语音识别算法不用兼顾远场拾音问题,可以得到相互最低影响的效果。当然若能再有骨传导上行降噪能力,肯定是美事一桩,完美的不要不要的了。
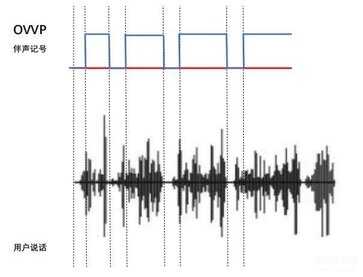
伴声记号可以通过蓝牙送到手机端,搭配麦克风信息数据,用在语音助手,自动录音,自动翻译,自动发送微信语音信息,语音输入法,驾驶模式,游戏……等各类语音相关应用。
OVVP 应用到的相关技术:
OVVP(Own Voice Vibration Peak-up)技术在应用上尊循一个最大的原则,就是不改变任何原有的声音处理路径上的信息数据参数结构,因为这些是多年积累下来的经验与技术结晶,任何的改动都有机会引发不可收拾的风险,碰触到众多人的利益,所以我们另辟一个新路径以辅助性角色为客户的 TWS 耳机在人工智能语音应用区块,以最完整专利配套零风险的为客户创造价值。
下方是在 TWS 耳机内 OVVP 的运作框架图:
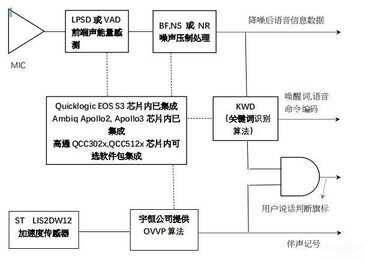
OVVP 算法技术细节简述
1)算法涉及卡尔曼滤波,FFT 极窄带声谱面积分割计算,曲线拟合,为了不惊动蓝牙芯片原厂能让算法直接用于蓝牙芯片应用层。通过泛化,降维,查表,不断优化简省整体延迟时间,使用内存资源,功耗及算力,从算法做出功能到给客户做测试, 1年多的时间才逐渐成熟,更别说骨传导上行降噪了。
2)加速度传感器感测到 感测到的X,Y,Z三轴声带运动信息数据,亦涉及X,Y,Z 三轴信息亦涉及互相关及归一化。
3)在最少影响极窄带区间频响的条件下,如何有效的将加速度传感器感测到的声带运动信息数据与用户自体运动所带起的多次谐波及喇叭串扰间进行分辨与压制。
三、语音算法各家公司专利保护重点分析
苹果专利的完整程度及保护范围级为完美, WO2014051969A1,201380046944.6 这2个专利把使用加速度传感器本地唤醒词与上行降噪应用保护的滴水不漏,从带算法芯片,方案,模块,产品到销售整个链条都被包含进去。
知名上市公司需要非常慎重的对待,对提供使用传感器做骨传导降噪或 VAD 应用的一定需要查询清楚是否有足够保护的专利或请对方提出具备闪躲苹果专利的具体对策,签署不侵权保证书,同时给出承担被诉后损失的承诺,项目负责人简单的问方案商有没有专利问题。
另外对于使用 vpu 做 VAD 当然就需要查看确认华为的 201811199154.2 专利,要特别提醒的是苹果的2个专利一样覆盖到了 vpu 基本上耳机用任何加速度骨传导传感器的上行降噪或 VAD 都被包含在内。
当然,用MEMS 加速度传感器做 VAD 宇恒公司的 200910190129.2,201810437831.3 也是特别需要去关注的。
专利侵权的判断中许多人员(特别是工程师或技术人员)会容易遇到认知误区,认为使用的技术比权利要求上的技术特征多,方法不完全相同,就不侵权。
其实侵权的判定是只要专利证书有效合法,满足权力要求内所有技术特征或技术框架,不管再往上叠加多少技术,不管你知道这个技术或应用技巧再久,专利没有被无效之前,侵权都是成立的。
另外技术特征或技术框架的判定有相同(完全一样)及等同(相似),“等同”这里允许一定的模糊空间,若有争议则可以再从专利说明书内去补充或其他行业信息内去举证。
之所以以前行业内专利侵权诉讼不多或经常不了了之,是因为举证成本,审理时间相对于产业变化速度及回报效益不成比例。
但现在整体智识产权维权大环境有了结构性的改变,就算不能短时间内在法院取得胜诉判决,在电商渠道却可以很快的斩断侵权者的利益,商誉及市占率的大量丢失。
特别是 TWS 耳机 AirPods目前已经成为苹果公司营收最重要的上升机会,该公司应对侵权会实施更加严苛的方式。
上市公司或知名企业的项目负责人需要慎重,以免对任职企业造成巨大伤害,而解决专利侵权的办法只有自己提早佈局创新,或合法取得授权及购买拥权产品,别无他法。
下方列出近 一年国内专利保护较重大的变化:
1、2019 年 1 月 1 日开始实施的电商法(关联法条 41 条~45 条)
2、38 个部门和单位联合印发《关于对知识产权(专利)领域严重失信主体开展联合惩戒的
合作备忘录》
3、深圳经济特区知识产权保护条例(经市第六届人民代表大会常务委员会第二十九次会议于
2018 年 12 月 27 日通过,并将于 2019 年 3 月 1 日实施其中关联法条 19~27,43~46)
新的仲裁单位与诉讼法院有:
3-1、2018 年 12 月 25 日成立的中国(深圳)知识产权保护中心
3-2、2018 年 7 月 28 日在琶洲环球贸易中心成立的广州互联网法院
3-3、2018 年 9 月 09 日北京互联网法院挂牌成立
四、专利侵权分析
1、苹果公司专利 201380046944.6
使用专利摘要,专利说明书及个人音频设备唯一独权内的技术特征做分析,专利内用了一个模糊的字眼,骨传导拾取换能器,在说明书[0005]条尾端也提到了加速计,这个专利适用的对象是 TWS 耳机成品制造商,只要用到骨传导拾取换能器(包含了 MEMS 加速度计及 vpu),并用到专利中的 20 条权利要求中的某条权利,基本上就会导致侵权。
其中很关键的地方是,使用“软材料”在壳内填充改善传感器取得声带振动所产生声波的效果,这点要请声学研发人员特别关注,这是搞声学的人最常用的手段,而下图表示 TWS 耳机厂家可能拿骨传导拾取换能器来做的 6 种功能,都在苹果专利的保护范围内。
苹果公司专利 WO2014051969A1
使用专利摘要及 2 个独权及权利要求 2.5 内的技术特征做分析,这个专利用了 37 个权利要求主要保护 VAD,噪声抑制及清浊音互融的应用,基本上只要用了加速度计(MEMS,vpu 都算)及麦克风就满足权利要求的技术特征,其中权利要求 5 把麦克风阵列给补充了进去。
所以看到这几个权利要可以很明确的说,不管骨传导上行降噪算法的提供者用的是 MEMS 或vpu 加速度传感器加上麦克风(不管是 1 个或多个)都是侵权。
当然,若是不用麦克风或加速度传感器其中任何一种传感器,就有机会闪躲掉这个专利,更好的办法是拥有比苹果更早的专利做保护,这个专利强的地方是判断侵权非常简单,不用找专业鉴定单位就可以做出清楚的侵权判断。
目前推测苹果公司有 2 个方法可以选择:
方法1:
拉出电商法,通过各电商平台的维权渠道投诉,就可以很快的让侵权产品下架,判断方法是,先看产品规格或功能介绍有没有 VAD,噪声抑制功能若有,则再看产品内有没有加速度计(MEMS 或 vpu),若有,就是侵权了。
上电商平台投诉渠道买个侵权产品拆解拍照写好侵权对比书,上传,15 天内被诉商家提不出反投诉或相应不侵权证据,侵权产品就等着下架吧,省钱有效。
方法 2:
直接从市场取证,鉴定,上法院起诉,交压金,封所仓库。
知名品牌厂商如:HUAWEI华为,VIVO,OPPO,联想,小米客户群体与苹果重叠面积较大,苹果的更为重视。
关于华强北的市场,因为客群与苹果不重叠,被投诉主体太小,可以起到帮苹果培养未来潜力客户。
这项专利很严格,需要市场上的同行谨慎规避。
2、华为公司专利 201811199154.2
使用专利摘要及 1 个方法独权 14 及权利要求 15 内的技术特征做分析,华为这个专利可以用图穷匕见来形容,前面系统独权 1 及权利要求 2~13 基本上好闪好躲又多属芯片内的处理或算法软件,不易取证鉴定,但是方法独权 14 及权利要求 15 同样的非常严格,容易涉及侵权。
把重点突显在使用骨振动传感器来控制拾音设备开始拾音,这个权利要求满足 TWS 耳机行业内极为关键的低功耗要求,华为在专利说明书[0047]条里提到 Sonion 公司的骨传导传感器,就是 vpu 了。
所以华为这个专利侵不侵权很好判,首先确定是否有 vpu,然后用实体耳机通过量电流的方式确认,说话前后的电流差别及比对麦克风的拾音时机即可。
所以想利用 vpu 做 VAD 来降低功耗的方案,估计不好实现,另外这个专利的权利要求 2~13 条其内每条都是算法或功能性软件,华为将这些算法或功能软件逐条拆解成权利要求,也方便他日后使用专利维权打击对手。
3、宇恒公司专利 200910190129.2
使用专利摘要及 2 个独权内的技术特征做分析,使用加速度传感器,感测声带,双击或计步运动,通过算法处里计算后,查找(判断,对比)是否落在预设阀值区间,得出用户“何时说话”判断结果,协助决定语音助手键码或何时说话判断结果(命令字)是否要通过蓝牙传送到手机。
只要依据加速度传感器获取用户声带运动的 VAD,做为“是否传送出语音助手键码的参考或何时说话判断结果”,不管是否还带有上行降噪功能都算是侵权,这个专利的申请时间落在 2009 年,是个能够攻防一体的专利。
宇恒公司专利201010224769.3,201010224780.X,201010224803.7,201010230464.3,
201010243048.7,201120374763.4,包含进去了加速度,陀螺仪,地磁仪,气压计多种惯性传感器感测声音的应用,申请时间都落在 2010 年~2011 年,能在传感器 VAD 应用上,起到绝佳的防御作用。
有兴趣做骨传导上行降噪算法的团队或公司,宇恒互动有兴趣将专利提供出来,一起研究如何用这些专利组合找出方法,至少先在中国突破苹果专利封锁,增加谈判筹码,降低自己及未来客户的风险。
宇恒公司专利 201810437831.3使用专利摘要及 2 个独权与权利要求 16 内的技术特征做分析,使用 1 个或 2 个,单轴或多轴,模拟或数字加速度传感器来感测声带振动和/或人体面部皮肤肌肉及肢体运动,产生传感器 VAD 的控制信号,不管用的是 MEMS 或 vpu 加速度传感器及是否还带有上行降噪功能都算是侵权。
使用 MEMS 或 vpu 加速度计做 VAD 或上行降噪应用,先把专利风险考虑完,再看这些应用是否满足功能指标要求,系统性充分全面的测试过再用声结构的改变是非常难实现的。
海内外知名人工智能语音应用巨头,在对OVVP算法了解过程中,非常着重要求专利说明,显然这个问题对这类企业来说影响很大。
总结
随着旗舰手机逐渐取消3.5mm接口以便实现轻薄化的趋势,续航、传输、音质、价格等痛点得到了改善,对整个TWS耳机市场的放量带来了巨大的成长空间。
根据GFK数据,2016年无线耳机出货量仅918万台,市场规模不足20亿元。到2018年无线耳机出货量同比增加41%,市场规模将达54亿美金。到了2020年TWS无线耳机的市场规模将达到110亿美金。
智研咨询预计2018-2020年全球TWS耳机将实现高速增长,出货量分别达到6500万台,1亿台和1.5亿台,年复合增速达51.9%。预计随着 无线耳机音质,功能性持续改善及与人工智能语音APP应用深度扩展联结,未来无线耳机的渗透率有望继续提升。
这样巨大的销量增长空间,让每一个想要入局有实力的厂商都有可能抓住商机,风口起飞。