








作为RTX 30系最强显卡,虽几经波折,现在终于和我们见面了。今天为大家带来的是技嘉GeForce RTX 3090 Ti GAMING OC魔鹰 24G评测。

本次RTX 3090 Ti的发布与其他RTX 30系显卡都有所不同,首先全部AIC都采用了全新的单16pin供电接口,我们大致猜想,这应该也是为后续RTX 40系显卡发布的一次“练兵”。其次,大部分厂商都为这次新显卡的发布重新设计了外观,包括本次评测的魔鹰同样在列。
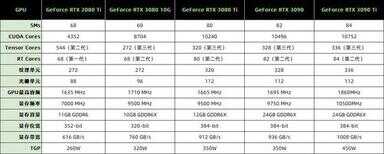
规格方面,RTX 3090 Ti毫不意外的采用了满血GA102核心,84组SM单元,比RTX 3090多了2组,同时频率和功耗也都有所增高。换来的则是相当暴力的性能提升,这一点我们在后面测试的时候展开细说。
这张RTX 3090 Ti拥有24GB大显存,依然定位于内容创作者。但如果你就是有钱,不在乎性价比,就要最好的,这张RTX 3090 Ti在游戏方面的表现同样有非常高的提升。

技嘉GeForce RTX 3090 Ti GAMING OC魔鹰 24G
技嘉GeForce RTX 3090 Ti GAMING OC魔鹰 24G这张显卡的售价为15999元,相比RTX 3090来说,售价基本相同,还挺“划算”,毕竟性能提升非常大。
在评测开始前,笔者先还是先将这款显卡的特点列出方便大家阅读:
- 1.新16pin供电设计,采用新ATX3.0电源标准,通过附赠转接线可兼容旧型号电源;
- 2.24GB大显存,轻松应对8K HDR游戏及内容创作软件
- 3.支持ECC校验,增加专业软件领域稳定性
- 4.1905MHz高频率,高于官方1860MHz标准频率
很多用户感觉这张显卡会不会来的太晚了些?距离RTX 30系显卡的发布已经过去了将近两年,而RTX 40系的新品也是箭在弦上。
但NVIDIA官方已经宣布,即便日后发布RTX 40系显卡,RTX 30系也将同时售卖。所以猜测,两代显卡在价格和性能方面不会出现太多重叠,而像RTX 3090 Ti这种TITAN级别的显卡,更不会参与游戏卡的竞争,所以它所面对的仍然是RTX 40系内容创作卡。
01 NVIDIA Ampere架构的 满血GA102核心
技嘉GeForce RTX 3090 Ti GAMING OC魔鹰 24G显卡采用了NVIDIA Ampere架构,我们首先来看一下这次的GA102核心。

RTX 3090 Ti算力对比TITAN RTX
相较于上一代Turing RTX架构的,NVIDIA Ampere架构在算力上有着成倍的增长,GeForce RTX 3090 Ti的着色器性能达到40 TFLOPS单精度性能,而搭载NVIDIA Turing架构的TITAN为16.3 TFLOPS。
RT Core达到78 RT TFLOPS。而且第二代光线追踪最重要的不仅仅是性能提升,还增加了对游戏中运动模糊部分场景的光线追踪计算加速。
全新的Tensor Core可自动识别并消除不太重要的DNN权重,处理稀疏网络的速率是Turing的两倍,算力高达320 Tensor TFLOPS。

RTX 3090 Ti显存对比TITAN RTX
同时在显存方面,RTX 3090 Ti也采用了24GB GDDR6X显存,显存频率达到了21 Gpbs,带宽则是史无前例的1 TB/s,让这款显卡可以畅玩8K 60帧游戏。
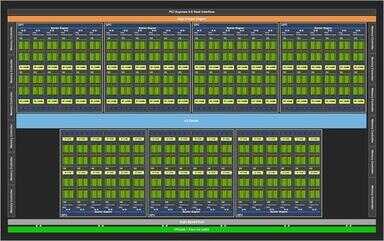
RTX 3090 Ti所采用的GA102核心
GA102的完整核心图NVIDIA在RTX 3080发布时就已经公布,现在终于有显卡应用到了未阉割的GA102。完整的GA102 GPU包含7个GPC(图形处理集群)42个TPC(纹理处理集群)以及84个SM(流处理器),CUDA数量为10752个。下面我们再来看看几款显卡的核心参数对比。
GA102核心拥有280亿(28000 million)个晶体管,628m㎡的面积,基于三星的8nm NVIDIA定制工艺,来自Micron的GDDR6X显存。
02 技嘉GeForce RTX 3090 Ti GAMING OC魔鹰 24G概览
首先开箱,在配件方面,除了常见的金属显卡支架外,由于本次在非公版显卡中首次搭载了单16pin供电接口,所以还配备了一根单12pin转8pin*3的转接线,不过两头都接上后,这一段会“支棱”着,装在机箱里还是比较明显的。

包装内配件
目前Intel已经发布了ATX电源3.0的新标准,就是需要有新的单16pin的显卡供电,目前已经有部分旗舰电源应用到,但普及尚需要些时间。不过相信不久后即便是RTX 3090 Ti的450W功耗,只接一根外接供电就够了。

技嘉RTX 3090 Ti 魔鹰24G
技嘉RTX 3090 Ti 魔鹰24G的外观进行了重新设计,相较之前的魔鹰,整体更“丰满”了一些,导流罩整体采用黑色和银色点缀,整体为金属拉丝工艺。显卡尺寸为331×150×70mm,占用3槽空间。相较于其他RTX 30系产品来说,仍然属于“巨无霸”级别。

技嘉RTX 3090 Ti 魔鹰24G风扇特写
并且由于这款显卡更是定位旗舰游戏,在散热方面也更加下功夫,三个主动散热风扇均采用了100mm刀刃式风扇,搭配正逆转功能,可在相同的风扇转速下获得更大的进气量。同时风扇内部的双滚珠轴承结构比传统结构具有更好的耐热性和效率。

技嘉RTX 3090 Ti 魔鹰24G侧面特写
内部的主动散热部分,技嘉RTX 3090 Ti 魔鹰24G采用均热板直触技术,加上8根复合式热管的引导效果,能提供更高的散热效率。

技嘉RTX 3090 Ti 魔鹰24G背板展示
技嘉RTX 3090 Ti 魔鹰24G的金属背板相较RTX 30系的其他几款产品有所不同,为了配合此次的“异形”PCB板,采用了大面积镂空的进气格栅,更有利于热空气排出。

单16pin供电接口
技嘉RTX 3090 Ti 魔鹰24G是首次采用单16pin接口的非公型号,从视觉效果来看,更简洁更美观。目前新的PCIe 5.0的电源规范为12+4pin的完整供电,其中最上面的4pin为讯号线,用于检测12V功耗是否可以满足显卡使用,新一代支持这个标准的电源会自带16Pin的供电线。所以目前全部采用8*3pin转12pin的转换线。

DP1.4a*3+HDMI 2.1
视频输出接口依旧采用了DP1.4a*3+HDMI 2.1的四接口设计,另外由于新的HDMI 2.1协议,最高已可支持单线8K的视频输出。
03 3DMARK理论性能测试
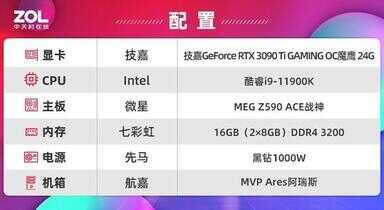
首先介绍一下测试平台,为了保证此次评测能够发挥3DMARK理论性能测试显卡的最佳性能,主板和CPU采用了11代桌面旗舰级配置,并且将内存容量提升至32GB,具体如下:
在测试成绩上,基准测试采用3DMARK,游戏性能测试使用游戏自带Benchmark,同时为了减小误差,每项测试成绩均测试3遍取平均值。
GPU-Z参数
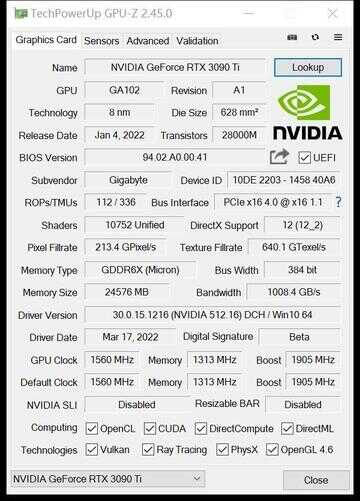
首先看一下GPU-Z的参数,技嘉RTX 3090 Ti 魔鹰24G采用GA102核心,三星8nm工艺,芯片面积628平方毫米,拥有10752个CUDA,Boost频率达到1905MHz,相较公版的1860MHz有较大提升。采用12GB GDDR6X显存,位宽为384bit,显存带宽达到了1008.4 GB/s,光栅单元和纹理单元为112和336。
下面先进行的是用来衡量显卡DX11理论性能的3DMARK FS套装:FS,FSE,FSU三者分别对应显卡在1080P、2K、4K的理论性能,取显卡分数实际测试结果如下:
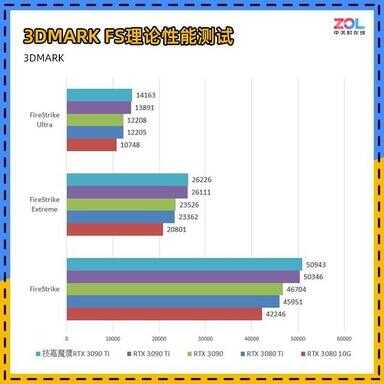
3D MARK FS套装测试
在针对显卡DX11性能的3DMARK FS套装测试中,测试结果大大超出了我们的预期,本以为RTX 3090 Ti的成绩会像RTX 3080 Ti到RTX 3090的跨度,没想到提升如此大。
技嘉RTX 3090 Ti 魔鹰24G相较RTX 3090综合提升12%,作为本代Ti后缀的型号,除了RTX 3060 Ti,3090 Ti是提升最大的,而且这还是在没有更换核心的情况下。
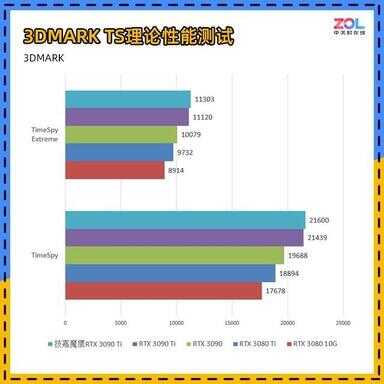
3D MARK TS套装测试
而在针对DX12环境下的Time Spy和Time Spy Extreme测试中,技嘉RTX 3090 Ti 魔鹰24G相较RTX 3090提升约为11%。
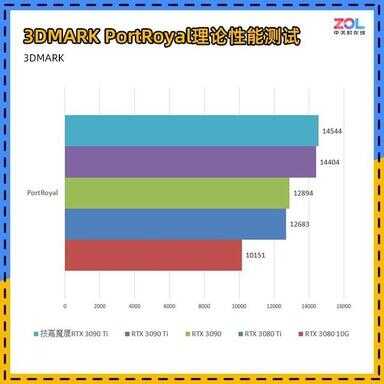
3D MARK 光追测试
PortRoyal是3DMARK中专门针对光追性能的测试项,技嘉RTX 3090 Ti 魔鹰24G相较RTX 3090提升约为12.7%。
综合来看,RTX 3090 Ti相较RTX 3090的提升几乎相当于更换了芯片,但其实两个型号的芯片只相差2组SM单元,更多的是暴力提升了功耗和核心频率,但结果也显而易见。
04 游戏性能测试
在游戏性能测试中,我们选择了《地平线5》、《刺客信条:英灵殿》、《无主之地3》,国产游戏《边境》、《光明记忆:无限》的benchmark跑分软件。
虽然这张RTX 3090 Ti显卡并不是为游戏玩家所准备,但此次大幅度的理论性能提升,也不禁让人好奇,在游戏中这张卡会有怎样的表现。
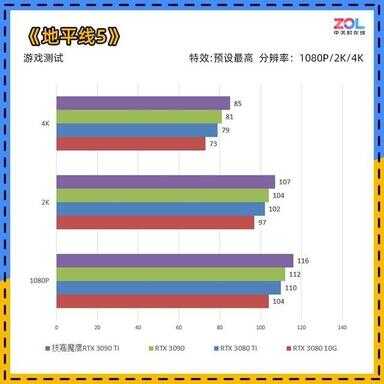
《地平线5》游戏测试
首先在《地平线5》中,技嘉RTX 3090 Ti 魔鹰24G显卡的1080P成绩相较RTX 3090再提升4%;2K分辨率成绩提升3%;4K分辨率成绩提升5%。
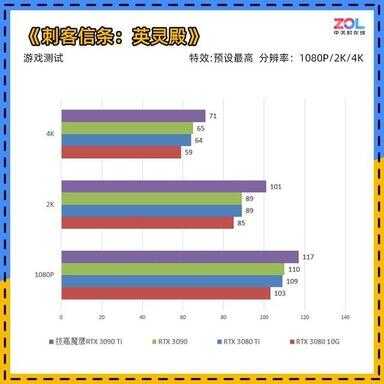
《刺客信条:英灵殿》游戏测试
在《刺客信条:英灵殿》中,可能由于驱动版本的更新和游戏更新,所有跑分相较以前的成绩均有大幅度提升,我们以本次跑分成绩为准。
技嘉RTX 3090 Ti 魔鹰24G的1080P成绩相较RTX 3090提升6%;2K分辨率成绩提升13%;4K分辨率成绩提升9%。
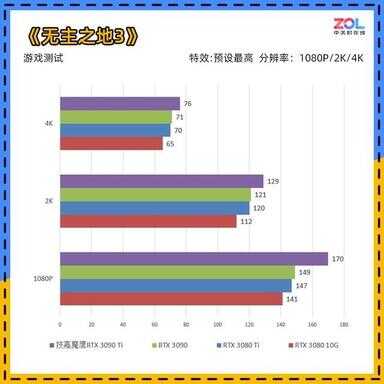
《无主之地3》游戏测试
《无主之地3》是一款采用了卡通渲染风格的游戏,它对于性能要求的下限很低而上限又很高,技嘉RTX 3090 Ti 魔鹰24G的1080P成绩相较RTX 3090提升14%;2K分辨率成绩提升7%;4K分辨率成绩提升7%。
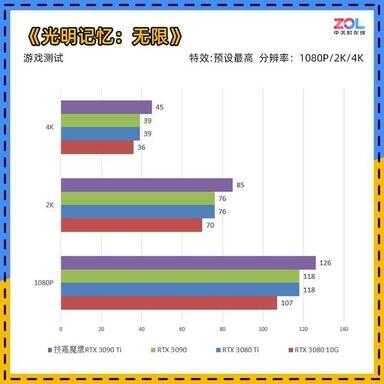
《光明记忆:无限》游戏测试
《光明记忆:无限》是由飞燕群岛工作室开发的《光明记忆》新系列,正式版已经在steam发售只要48元,属于小品级游戏中的大制作。
技嘉RTX 3090 Ti 魔鹰24G的1080P成绩相较RTX 3090提升7%;2K分辨率成绩提升12%;4K分辨率成绩提升15%。
不过即便强如RTX 3090 Ti,在4K分辨率下也没有达到60帧。《光明记忆:无限》的benchmark测试似乎将光线追踪用到了极致。
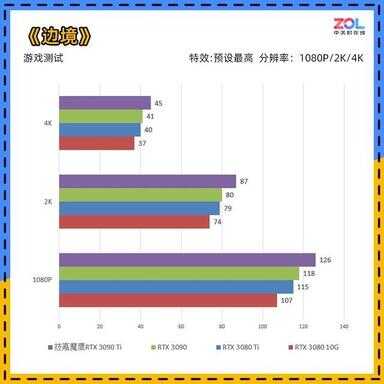
《边境》游戏测试
在另外一款国产游戏《边境》的跑分软件中,情况基本与《光明记忆:无限》相同,测试条件均在“RTX最高/DLSS质量”下进行。
技嘉RTX 3090 Ti 魔鹰24G的1080P成绩相较RTX 3090提升7%;2K分辨率成绩提升9%;4K分辨率成绩提升10%。
在整体游戏方面,NVIDIA官方给出的游戏数据是在标频情况下提升约为4-8%,而我们测试的技嘉RTX 3090 Ti 魔鹰24G在1905MHz频率下,综合提升约为10%,与理论成绩基本相符。
所以尽管RTX 3090 Ti的定位依然是内容创作显卡,但它的性能提升是实实在在的,如果不考虑性价比的话,入手一张绝对是本代最强游戏卡。
05 专业软件测试
除了光线追踪的强化,NVIDIA Ampere架构的Tensor Core也得到了极大地加强,在第三代Tensor Core中,NVIDIA引入了稀疏化加速,可自动识别并消除不太重要的DNN(深度神经网络)权重,同时依然能保持不错的精度。首先原始的密集矩阵会经过训练,删除掉稀疏矩阵,再经过训练稀疏矩阵,从而实现稀疏优化,进而提高Tensor Core的性能。
同时,显卡的一个重要指标是显存容量和位宽,显存位宽越大,表示单位时间显卡能处理的数据的越多,RTX 3090 Ti拥有384bit 位宽,带宽为 1008.4 GB/s,以及24GB大显存,这都为内容创作提供了更好地助力。
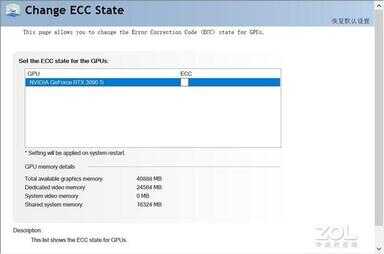
NVIDIA控制面板中新增ECC开启功能
另外此次RTX 3090 Ti也是NVIDIA在RTX 30系中首次为消费级显卡开启ECC显存校验,开启这一功能后,显卡性能会有所下降,但稳定性会增加,更有助于在专业软件中长时间稳定工作。

NVIDIA Omniverse
在此次GTC 2022大会中NVIDIA也正式向开发者推出NVIDIA Omniverse实时设计协作和模拟平台,它可轻松构建自定义工具,以简化、加速和改进其开发工作流。更多关于Omniverse的使用体验和链接方法,可以参考笔者之前的文章“NVIDIA Omniverse体验 老板监工神器”,这里就不过多讲解了。
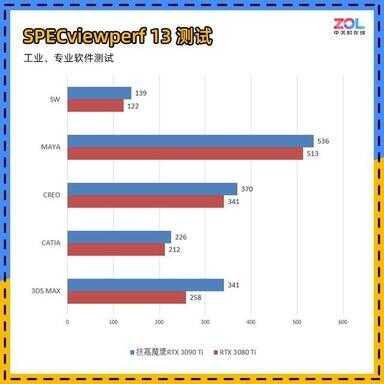
上图为笔者使用SPECviewperf 13这款工业、专业软件跑分测试。对比显卡为本代的游戏旗舰RTX 3080 Ti和生产力工具旗舰RTX 3090 Ti。
从结果来看,两款显卡相差不大,但测试环境都是在不爆显存的情况下得来,毕竟RTX 3080 Ti同样使用的GA102芯片,也是本代最强的游戏旗舰卡。另外如果在更高分辨率下的渲染中,大显存的优势才会突显,当显存溢出时,通常不像游戏只是卡不卡的问题,而是能不能用的问题。
KeyShot 9测试

KeyShot 意为“The Key to Amazing Shots”,是一个互动性的光线追踪与全域光渲染程序,无需复杂的设定即可产生相片般真实的 3D 渲染影像。
KeyShot 9有预设模型,进入软件后直接点击渲染,为了更考验大显存所带来的帮助,我们直接将渲染分辨率改为预设的7680×7680方形8K尺寸。
同时在选项中,选择GPU渲染,可以看到目前正在采用RTX 3090 Ti进行渲染,而GPU使用量为100%

技嘉RTX 3090 Ti 魔鹰24G渲染时间为1分43秒
在预设模型的渲染中,可以看到整个过程的渲染时常为1分43秒,其中在渲染时的显存占用为17.1GB,已经远远超出了RTX 3080 Ti的12GB,也让笔者不由得期待超出显存后会是什么样。

RTX 3080 Ti渲染崩溃
在使用RTX 3080 Ti后,由于渲染8K分辨率图片的显存严重溢出,会导致软件无法渲染,直接崩溃。虽然在KeyShot 9中软件崩溃没有比较明显的提示,但通过这重叠的窗口用户也能大体看出端倪了。
DaVinci(达芬奇)测试

DaVinci(达芬奇)是世界上专业8K编辑的唯一解决方案,集成颜色校正,视觉效果,音频编辑在一个软件中。
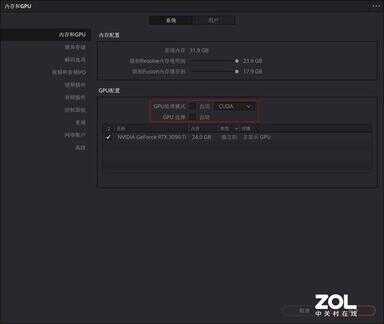
首先在偏好选项中,取消勾选自动的GPU配置,指定使用技嘉RTX 3090 Ti 魔鹰24G显卡。
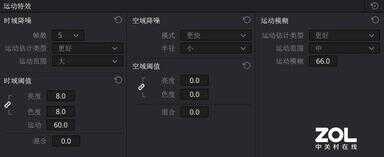
导入一段高清的8K素材后,在运动特效中增加时域降噪、时域阈值以及运动模糊的参数,下面先来看RTX 3090 Ti的演示效果。
技嘉RTX 3090 Ti 魔鹰24G可流畅预览
这一段8K素材的可调色空间非常大,笔者增加了一层电影滤镜,可以看到在使用RTX 3090 Ti时,可以在实时预览时达到非常流畅的程度。
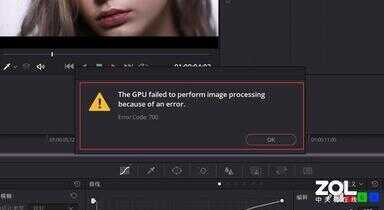
RTX 3080 Ti预览崩溃
在分辨率越高的情况下,实时预览对显卡显存的要求也就越高,RTX 3080 Ti采用12GB显存会出现报错,这就是因为显存不够。
在显存不够报错的情况下,解决办法基本只有创建代理进行剪辑,不过这样无法展示素材的最真实效果,所以在超高分辨率下,拥有24GB大显存的RTX 3090 Ti拥有绝对优势。
Blender测试

Blender是一个免费开放源码的3D创作套件。它支持整个三维编辑-建模,索具,动画,模拟 渲染,合成,运动跟踪,视频编辑和2D动画编辑。
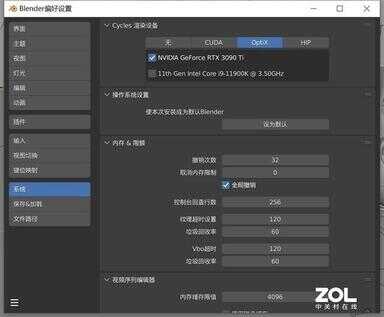
首先还是设置渲染设备,Blender默认使用CPU渲染,这里选择RTX 3090 Ti。
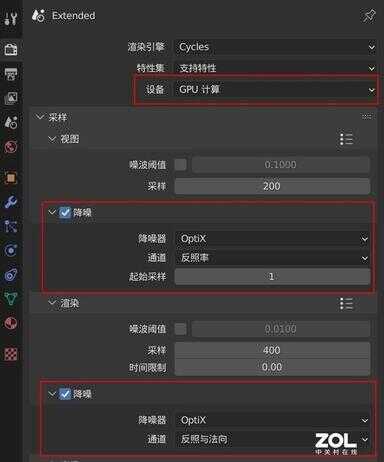
在软件内的渲染设置内,勾选两项降噪,并且为了增加渲染时常,我们将采样率提升至400,渲染分辨率提升为200%。

技嘉RTX 3090 Ti 魔鹰24G渲染时长为1分21秒

RTX 3080 Ti渲染时常为1分29秒
在第一组测试中,技嘉RTX 3090 Ti 魔鹰24G的渲染时常为1分21秒,RTX 3080 Ti的渲染时常为1分29秒,单独来看差异似乎不大,不过我们对比的为RTX 3080 Ti显卡,刨除显存的因素,这也是一张旗舰游戏显卡,算力非常强悍。

技嘉RTX 3090 Ti 魔鹰24G 渲染时长为1分40秒

RTX 3080 Ti渲染时常为1分49秒
第二组对比中为一段900帧的循环动画,并且分为第三人称视角和第一人称视角双镜头。这组对比中,单帧的差距仍然为9秒。
不过可能是自带运动模糊,增加了一定的显存使用率,所以在渲染时RTX 3080 Ti偶尔有报错的情况,只能重新渲染。

技嘉RTX 3090 Ti 魔鹰24G 渲染时长为1分32秒

RTX 3080 Ti渲染时常约为1分39秒
在同一帧下,第一人称视角与之前的时间基本相同,这里不做过多阐述。
在这段动画中,我们按照每帧渲染时间相差18秒(双镜头)来计算,一段900帧的动画渲染时常就会相差16200秒,等于270分钟或者4.5小时。
如果按1秒24帧来计算,那么这段动画也只有37秒左右。而在大型的动画电影中,庞大的数据量往往需要电脑夜以继日的渲染,即便是崩溃一次,可能也会浪费很久的时间,所以大显存在内容创作领域的优势显而易见。
06 功耗及温度测试
功耗测试中,我们选择FurMark软件进行拷机测试,并采用GPU-Z检测温度,功耗仅计算显卡自身。
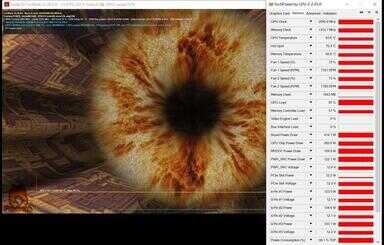
功耗测试(点击查看大图)
技嘉RTX 3090 Ti 魔鹰24G经过我们的实测在满载状态下单卡功耗为414W左右,但是可以看到下面新增的TDP项,GPU满载也只达到了86%的水平。所以根据这个来计算,如果达到100% TDP,实际为480W左右。
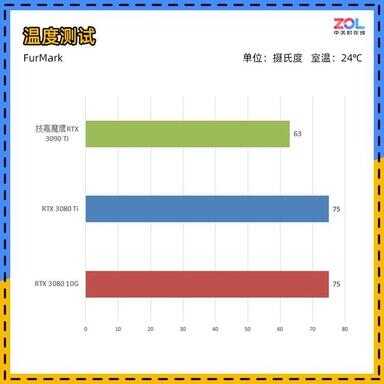
温度测试
温度方面,本次的技嘉RTX 3090 Ti 魔鹰24G经过25分钟左右的拷机,温度稳定为63℃左右,峰值达到65℃。另外显存温度为68℃,比核心温度还要低很多,可以说内部重要区域散热做得非常到位。
07 它来晚了吗?
对于RTX 3090 Ti的实测数据,相信大家还是比较意外的,毕竟本代的Ti系列除了RTX 3060 Ti,还没有性能提升如此大的。
虽然只差2组SM单元,但频率的大幅提升和功耗增加,这种简单粗暴的方式对于性能提升的影响显而易见。
另外很多用户感觉这张显卡会不会来的太晚了些?距离RTX 30系显卡的发布已经过去了将近两年,而RTX 40系的新品也是箭在弦上,现在发布RTX 3090 Ti寓意何为?

技嘉GeForce RTX 3090 Ti GAMING OC魔鹰 24G
首先个人猜测,这款RTX 3090 Ti更像是RTX 3090的改进版。在散热方面,由于RTX 3090采用了单颗容量1GB的显存,所以PCB版双面均有排布,发热量巨大,也更不好设计散热方案。
而本次的RTX 3090 Ti则采用了单颗2GB的显存,这也是为什么大家看到本次的RTX 3090 Ti拷机温度更容易控制。
另外NVIDIA官方已经宣布,即便日后发布RTX 40系显卡,RTX 30系也将同时售卖。所以个人猜测,两代显卡在价格和性能方面不会出现太多重叠,而像RTX 3090 Ti这种TITAN级别的显卡,更不会参与游戏卡的竞争。
所以它所面对的仍然是RTX 40系内容创作卡,大概率下一代的TITAN级别产品会更贵。
另外对比此前发布的RTX A6000显卡,不难发现两款产品其实采用了完全相同的核心,都是GA102,都是10752个CUDA,甚至Boost频率都是1860MHz,而目前RTX A6000在京东的售价为34799元,那么这两款产品到底有什么区别?

RTX A6000参数一览
显存方面,RTX 3090 Ti相比RTX A6000少了24GB显存,但由于采用了GDDR6X显存,带宽更高了,整体速度更快。原本专业卡独有的ECC显存校验,本次在RTX 3090 Ti中也得到了支持。不过vGPU显存是不支持的,这也是RTX A6000在专业卡上得天独厚的优势。
游戏方面,其实RTX A6000也有着不错的表现,如果你真的有钱,买一张A6000来打游戏也不是不可以,但它的帧数应该会比RTX 3090 Ti更低,同时散热表现也没有那么好。
但专业卡的长处在于各大专业软件的兼容和适配,以及内部调校。如Catia以及SW等软件针对专业卡都有非常好的优化,不过我们常见的3DSMAX和MAYA等软件,即使是消费级的RTX 3090 Ti同样有着出色的性能和稳定性表现。

技嘉GeForce RTX 3090 Ti GAMING OC魔鹰 24G
RTX 3090 Ti这张显卡的定位依旧是主内容创作者,尽管NVIDIA在各方面的宣传都没有提及游戏性能,但不可否认的是,此次RTX 3090 Ti在理论和游戏测试性能有着大幅度提升,均达到10%左右。
如果你想用它来打游戏,不追求性价比,只要极致性能,那么买一张也没什么问题。
技嘉RTX 3090 Ti 魔鹰24G这张卡在外观上进行了重新设计,相较于原来的魔鹰,整体黑色的造型更简约,但受制于散热效果的要求,显卡本身的厚度有所增加。所以这张显卡在散热方面的表现也让人印象深刻,在发热量最高的显存上,也只有68℃。
目前这张技嘉RTX 3090 Ti 魔鹰24G显卡的售价为15999元,其实相比目前RTX 3090的市价13999元来说,还是比较有性价比的。
08 附录1-光追及DLSS效果
上面我们测试了部分游戏的光追和DLSS性能表现,这些效果具体在游戏中是什么表现,下边笔者选择了两款游戏给大家展示一下。

《光明记忆:无限》RTX ON(点击查看大图)

《光明记忆:无限》RTX OFF(点击查看大图)
《光明记忆:无限》温泉场景中的光追效果是最为耗费显卡性能的。不难发现,最大的变化来自水中的倒影,而这一组倒影的计算难度非常高,由于并不是平静水面,所以要首先要考虑光线在水面的变化,其次与岸边鹅卵石的光线折射效果,最后则是综合前两种效果,将光线照射在水池底部。

《赛博朋克2077》RTX ON(点击查看大图)

《赛博朋克2077》RTX OFF(点击查看大图)
在《赛博朋克2077》中,光追效果随处可见,而在游戏中也运用到了不同的光追效果,包括最常见的光追反射、阴影,还有环境光遮蔽、漫反射照明以及全局光照等比较高级的效果。

RTX ON(点击图片查看大图)

RTX OFF(点击图片查看大图)
在网游《逆水寒》中,由于光追效果正处于试验阶段,并没有如宣传片一样的水面反射。但画面整体的阴影更加真实,如头顶树木的阴影,以及水面上荷叶的效果。而且由于光追效果较少,在打开该功能后帧数并没有明显下降。

《堡垒之夜》RTX ON(点击查看大图)

《堡垒之夜》RTX OFF(点击查看大图)
堡垒之夜的光追效果还是比较明显的,其中加入了反射、全局照明和路径追踪等效果。卡车车身上的反射较为明显,角色身上的环境光在打开光追后更为写实,另外仔细看的话远处建筑物的玻璃同样有光线的反射,整体画质改善非常明显。
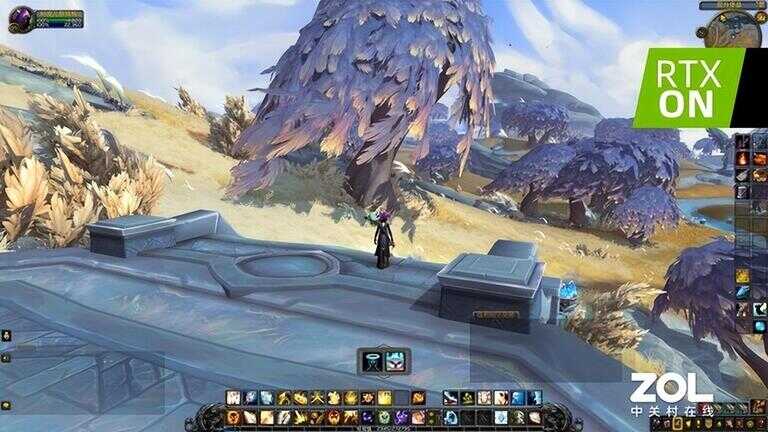
《魔兽世界9.0》RTX ON(点击查看大图)
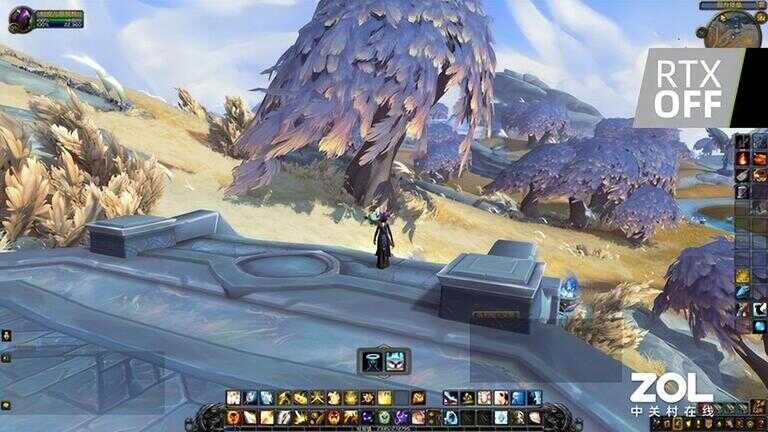
《魔兽世界9.0》RTX OFF(点击查看大图)
《魔兽世界9.0》同样作为一款卡通渲染的网游来说,魔兽的年代更加久远,此次加入光追效果在整体视觉上没有堡垒之夜明显。不过如远处的树木阴影,以及近处石台下方的阴影都比较明显。

《控制》RTX ON(点击查看大图)

《控制》RTX OFF(点击查看大图)
《控制》这款游戏所采用的引擎物理效果非常出色,同时光追开关的对比也是肉眼可见的明显。包括玻璃上的人物反光,远处地面的植物反光都比较清晰,同时打开光追后屋顶处的明暗对比也更加明显。


我们再来看看《彩虹六号:异种》各个DLSS模式下的画质表现。超级分辨率技术中,最难以把控的就是这种栅栏的细节部位,但是根据实测来看,即便是超级性能模式中,细节依旧清晰。可以看出较大差距的只有标识牌上的字体,在超级性能模式中,颜色边缘会有模糊的情况。
从帧数提升上来说,相比原生画质分别提升了55%/73%/88%/131%,对于游戏玩家来说,这简直是神迹!


接下来再提高难度,第一幅对比图的栅栏为独立建模,而此图中的棋盘格则是建筑中的花纹细节,可以看到在超级性能模式以上的细节把控都是比较到位的。而遍布地图中的菌毯在DLSS效果中也没有失真或模糊的情况。
帧数方面,相比原生画质分别提升了49%/85%/111%/162%。确实如NVIDIA所说,拥有了AI就拥有了未来,DLSS无论从画质表现还是帧数提升上来说,值得每一位玩家拥有。

《光明记忆:无限》在这一组对比中,在画面差距上,从DLSS关到DLSS性能依旧看不出什么变化,但是在超级性能模式中,墙壁的清晰度以及轮廓都有所下降。
当然总的来说,尽管DLSS贡献了非常大的功劳,但可以看得出《光明记忆:无限》在优化方面下了很大功夫,这对于靠一人主导的游戏来说难能可贵。

《赛博朋克2077》DLSS模式对比
《赛博朋克2077》这款游戏中,以2K/RTX ON/DLSS关闭 原生画质下作为标准,在打开DLSS质量模式后可以看到整体画面几乎没有任何变化,广告牌的字样边缘依然很清晰。在DLSS平衡和DLSS性能模式中依然有着不错的状态,整体相较原生画质并无二致。

《逆水寒》DLSS模式对比
画质说明
在《逆水寒》的DLSS测试中,我们将画面设置为4K分辨率,画质为预设最高。通过关闭、快速、超级性能,3种不同模式来进行帧数以及画面的对比。
首先在关闭DLSS中,游戏帧数为26帧原生画质,打开DLSS快速模式后为41帧,而打开DLSS超级性能模式后为57帧。通过放大图片不难发现原生画质和DLSS快速模式的区别很小,而DLSS超级性能模式中角色背后的装饰会变模糊,以及木条箱的纹理边界会有较明显变化。但帧数提升却非常明显。

《永劫无间》DLSS模式对比
在《永劫无间》的DLSS对比中,原生画质大家可以注意角色发带的编制质感,每一根发丝边缘都较为清晰,同时肩部的服装花纹也有较为明显的凹凸感。在DLSS打开后,由于其工作原理就是缩放后,再由AI算法放大进行边缘重建,所以在质量模式中,发丝就会丢失部分细节,但如果不细看很难发现,同时发带的细节也保留的相当完好。
而在DLSS性能模式中,头发的质感则更差一些,并且发带的编织感有明显下降,另外腰间的配置边缘也会变模糊。最后在DLSS超级性能模式中,角色整体则会较糊,无论是头发还是服饰,所以如果不是非常追求高帧数的玩家,不建议开启DLSS超级性能模式。
09 附录2-Ampere新特性
好的硬件没有软件的加持,相当于空有长柄没有枪头,想要发挥十成威力则必须软硬搭配,反之亦然。此次随着发布会共同推出的还有以下几项非常值得大家关注。
NVIDIA Reflex
以往我们关注延迟大多从显示器上了解到几毫秒极速响应,但那只是作为最终端的显示输出效果,你是否想过从系统内部到实际看到的画面有多大延迟?
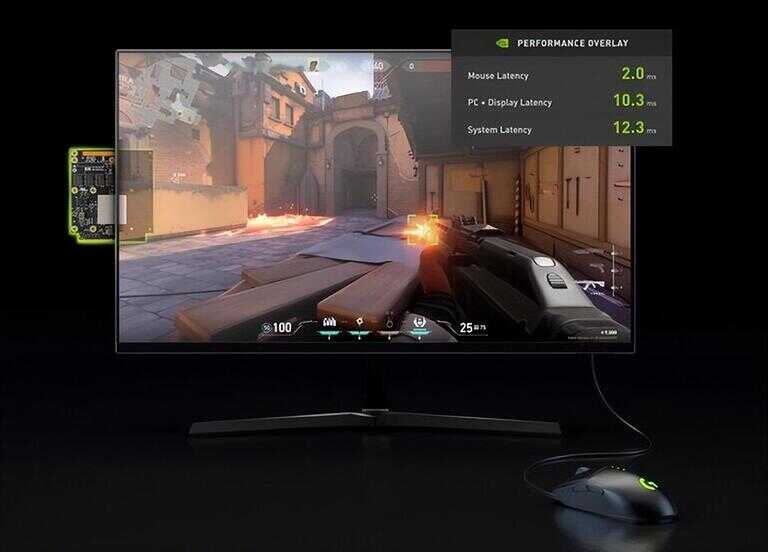
NVIDIA Reflex
在20系显卡中NVIDIA反复提及的“帧能赢”,在30系显卡中也做了更进一步的突破,除了NVIDIA将推出自己的电竞显示器NVIDIA 360Hz G-SYNC ESPORTS,还有NVIDIA Reflex技术。
以往如果想测量系统延迟需要高速相机以及定制的LED鼠标电路。而使用带有NVIDIA Reflex技术的显示器将内置精确的延迟分析工具,可在CPU和GPU中优化渲染管道,极大减少延迟时间,将系统延迟整体降低至30ms以下。不过就像图中所示,为此你需要一个支持反射延迟分析的鼠标。
NVIDIA Broadcast
NVIDIA Broadcast是一款易用且专业的直播软件,它的强大之处就在于主播不再需要任何的背景布置,只需要一个普通的摄像头和一张GeForce RTX系列的显卡即可。

宠物派对直播
这款软件可以让你杂乱无章的房间立即变成直播间,其内置了音频降噪、背景虚化、虚拟背景、头部追踪等功能。NVIDIA Broadcast的工作原理是利用AI算法通过DGX超级计算机深度学习而来。
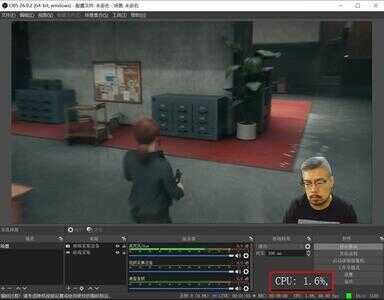
NVENC编码
同时RTX 30系显卡拥有目前最好的硬件解码器,大部分用户的电脑在直播时打开OBS推流后CPU占用会直接飙升到50%左右,而基于GPU的NVENC解码可以极大地减轻CPU负担。
NVIDIA Studio
对于内容创作者来说,提到软件可能大部分只会想到内容创作的相关软件,但NVIDIA专为内容创作者推出的NVIDIA Studio驱动则是承担着连接创作软件和显卡功能的关键。

NVIDIA Studio
NVIDIA Studio驱动经过更新与优化,对于最新版本的Adobe系列软件支持更为稳定,同时附带更出彩的创作功能。利用NVIDIA CUDA技术,GPU加速特效可实现更快的实时视频编辑并加速渲染输出,并让原本只能进行软件编码输出的视频轻松得到硬件的支持。另外在AI计算方面的优势,包括自动标记片段、特效追踪和人脸识别等功能,都有显著的速度提升。

以GPU渲染为14.98秒 而CPU渲染为11分钟
当然NVIDIA Studio的加速创作绝不止Adobe一家,DaVinci、Keyshot、Blender、D5等专业软件中都有非常亮眼的表现。不仅能提供强大且稳定的运行环境,更能以GPU加速,有效提升创作效率。