








经常和电脑打交道的朋友,一定有过这样的难题,在网上查资料找文章,复制文章的内容才发现必须要注册登录才支持,也太麻烦了吧!
这种限制复制文字的网页,其实是用JavaScripty代码来实现限制复制的,当然,解铃还须系铃人,今天教大家一串代码接触限制。
1、代码接触限制
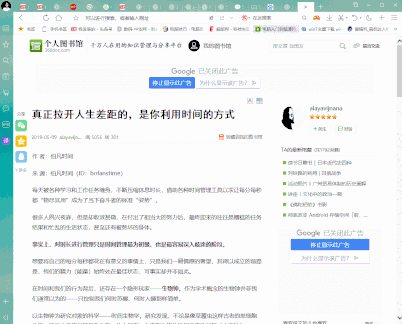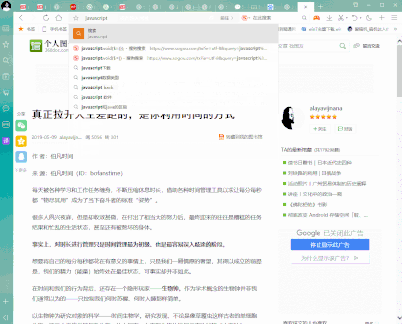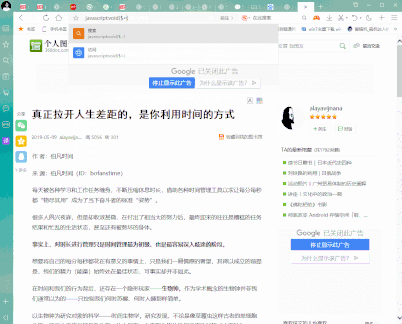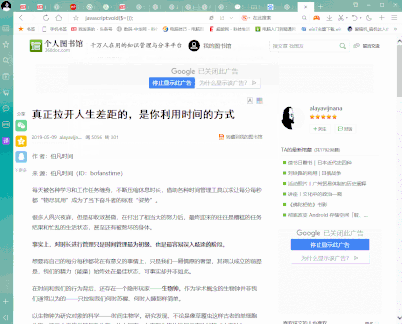
首先在我们需要复制内容的网页中的地址栏中输入:
javascript:void($={});
然后按下回车键Enter,然后网页的内容就可以支持任意复制啦!
2、通用识别方法
同样方法不仅支持提取网页中的文字,还能够提取书本、图片上面的文字,在书本中遇到需要摘抄到电脑的内容,也可以轻松提取,方法如下:
我们打开迅捷PDF转换器工具,在特色功能中找到"图片转文字",然后将网页的图片截图,或者书本中的内容拍照上传。
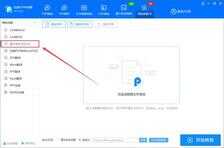
点击转换之后即可将文字输出到Word文档中,我们一起来看看效果:
3、在源文件中复制
还有一种方法,在网页中【右击】,然后点击【查看源文件】,接下来在源文件中找到对应的文字内容复制即可。
掌握好这3种方法,以后不用担心网页上的文字无法复制了