小伙伴们好啊,今天咱们来分享一个数据整理的实例。
昨天,函数正式课群里有位小伙伴发了这样一份考勤数据:

每个人全天的考勤数据都挤在一个单元格里,现在要计算每个人每天的实际出勤时间。
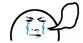
最终希望得到的数据是这样的:
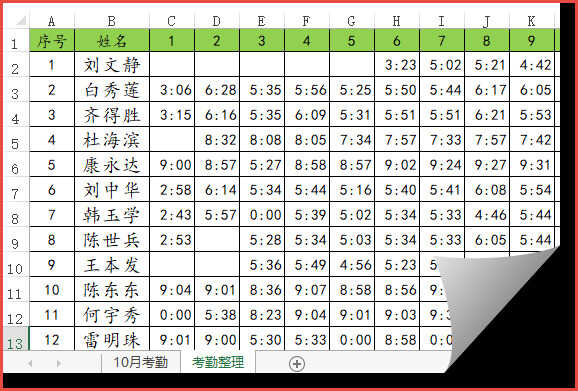
回过头来咱们观察一下数据结构,看看有没有可以利用的规律。
首先来看看K列姓名的规律:每个姓名之间都间隔一行:

利用这个规律,咱们就可以在“考勤整理”工作表里,使用公式提取员工姓名了。
在“考勤整理”工作表的B2单元格输入以下公式,下拉至出现空白为止:
=OFFSET('10月考勤'!K$5,(ROW(A1)-1)*2,)&""
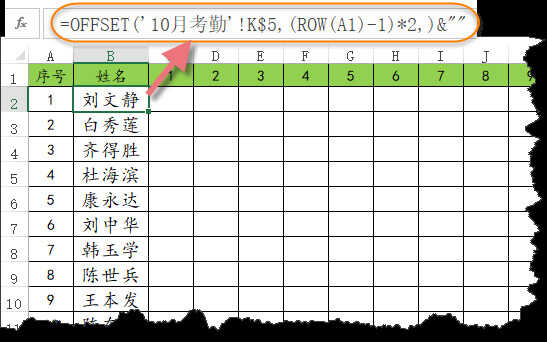
简单说说公式的意思:
(ROW(A1)-1)*2部分,计算结果为0,公式下拉时,会得到从0开始、按2递增的序号0、2、4、6、8……。
OFFSET函数以“10月考勤”工作表K5单元格为基准,以ROW函数的计算结果作为向下偏移的行数,也就是公式每下拉一行,就从“10月考勤”工作表K5单元格向下偏移两行。
当OFFSET函数引用空单元格的时候,会显示成无意义的0,所以在公式最后加了一个小尾巴&"",目的就是将这个无意义的0变成空文本,从而显示成空白了。

接下来就要提取每天的工作时长了, 咱们再来观察一下打卡时间的规律。
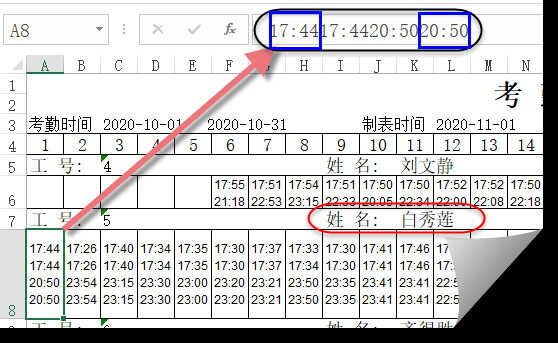
以“白秀莲”1号的打卡数据为例,打卡数据位于姓名的下一行,虽然有多次打卡记录,但是咱们看前5位,其实就是最早的上班时间,而后5位就是最晚的下班时间了。
接下来咱们先看看如何定位到这个打卡时间所在的单元格:
=INDEX('10月考勤'!A:A,MATCH($B2,'10月考勤'!$K:$K,)+1)
MATCH函数的作用是根据指定的查询值,返回该查询值在查询区域中首次出现的位置。
INDEX函数的作用是根据指定的位置信息,从一个区域中返回对应位置的内容。
公式中的MATCH($B2,'10月考勤'!$K:$K,)部分,利用B列已经提取出的姓名,借助MATCH函数计算出该姓名首次出现的位置。最后加上1,就是这个人的打卡记录所在的行了。
再使用INDEX函数,从“10月考勤”工作表的A列提取出该员工1号的打卡记录。

要从打卡记录中分别提取前 5位和后5位,这里需要使用LEFT函数和RIGHT函数。
LEFT函数的作用是从数据的左侧开始,提取指定位数的字符。
RIGHT函数的作用,是从数据右侧开始提取指定位数的字符。
先计算出下班打卡时间:
RIGHT(INDEX('10月考勤'!A:A,MATCH($B2,'10月考勤'!$K:$K,)+1),5)
再计算出上班打卡时间:
LEFT(INDEX('10月考勤'!A:A,MATCH($B2,'10月考勤'!$K:$K,)+1),5)
二者相减,就是每天的工作时长。
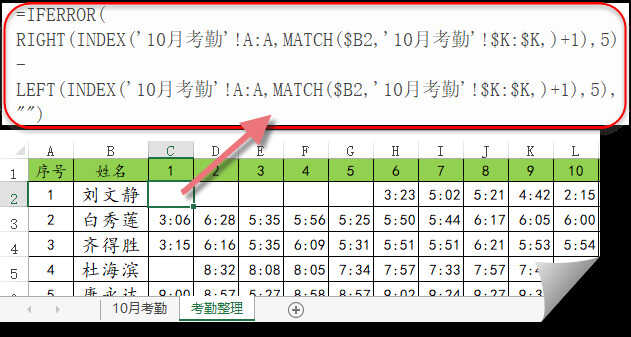
如果某一天的打卡记录是空白,RIGHT和LEFT函数会返回空文本,空文本再相减的话,就返回错误值了,所以要加上一个IFERROR函数,来屏蔽错误值。
最后咱们把以上两段公式组合一下,在C2单元格输入以下公式,向右向下复制即可:
=IFERROR(RIGHT(INDEX('10月考勤'!A:A,MATCH($B2,'10月考勤'!$K:$K,)+1),5)-LEFT(INDEX('10月考勤'!A:A,MATCH($B2,'10月考勤'!$K:$K,)+1),5),"")