








前言
不知各位看官在工作之中有没有陷入过疯狂CV代码、看着密密麻麻的类不想动手,或者把大把的时间花费在底层的情况。以笔者为例,会经常遇到以下两个问题:
隔一段时间就需要构建一个新应用,需要各种复制粘贴(缺乏定制化的脚手架)新需求一堆的Entity、Bean、Request、Response、DTO、Dao、Service、Business需要写,看着都不想动手很多时候甚至会在复制粘贴代码时漏掉一些关键的注解,比如:@Service,导致项目无法启动,再花费更多的精力去排查。因此本文将以实际工程代码为例,来构建一个可定制化,支持高度扩展的代码生成器。
项目目标
本项目将基于生成器项目生成一个可直接运行/可方便一键复制的SpringBoot成品项目,其中包括基本的数据库操作、业务操作及Web接口、视图层。
同时支持拔插式自定义实现,具备较高的拓展性,以下是项目基本结构:
Code-Generate├── pom.xml├── src│ ├── main│ │ ├── java│ │ │ └── com│ │ │ └── mysql│ │ │ ├── App.java // 程序入口│ │ │ ├── bean│ │ │ │ ├── ClassInfo.java // 类实体(对应表维度)│ │ │ │ ├── ConfigurationInfo.java // 配置中心│ │ │ │ ├── FieldInfo.java // 字段实体(对应表字段维度)│ │ │ │ └── GlobleConfig.java // 全局配置│ │ │ ├── engine│ │ │ │ ├── AbstractEngine.java // 抽象引擎│ │ │ │ ├── GeneralEngine.java // 接口引擎│ │ │ │ └── impl │ │ │ │ ├── CustomEngineImpl.java // 自定义引擎(拔插式基类)│ │ │ │ └── DefaultEngine.java // 默认引擎│ │ │ ├── factory│ │ │ │ ├── ClassInfoFactory.java // 类工厂(非必要,可融进上述配置中心)│ │ │ │ └── PropertiesFactory.java // 配置文件工厂(非必要,可融进上述配置中心)│ │ │ ├── intercept│ │ │ │ ├── CustomEngine.java│ │ │ │ └── impl│ │ │ │ ├── DataMdImpl.java // 自定义引擎案例一(数据库文档)│ │ │ │ └── LayUiHtmlImpl.java // 自定义引擎案例二(视图界面)│ │ │ └── util│ │ │ ├── DataBaseUtil.java // 数据库依赖│ │ │ ├── DBUtil.java // 数据库操作类│ │ │ ├── IOTools.java // 工具类│ │ │ └── StringUtil.java // 工具类│ │ ├── resources│ │ │ ├── application.properties // 配置文件│ │ │ ├── log4j2.xml // 日志配置│ │ │ └── templates // 模板目录│ │ └── test│ └── META-INF └── MANIFEST.MF // META-INF文件,为了打成Jar包使用(非必须)复制代码编码
构建配置中心
由于本项目涉及数据库操作层等,因此除了目标目录,项目名,作者,根目录等基本参数外,还需要数据库相关配置等,配置文件如下:
# 数据库IP, 数据库Driver, 编码, 用户名, 密码ip=127.0.0.1port=3306driver=com.mysql.jdbc.DriverdataBase=school-miaoencoding=UTF-8loginName=rootpassWord=# 需要构建的表名 为* 默认包含全部, 以;号隔离比如: a;b;c;d;include=*;# 项目名projectName=Demo# 包名packageName=com.demo# 作者authorName=Kerwin# 项目输出根目录rootPath=F:\\code# 自定义Handle包含项, 现有自定义模块:DataMdImpl,LayUiHtmlImpl, * 号默认包含所有,以;号隔离比如: a;b;c;d;customHandleInclude=DataMdImpl;LayUiHtmlImpl;复制代码考虑好基础的配置内容后,通过读取文件配置,将相关信息置入配置中心即可,具体代码便不再展示,需要的直接观看源码即可(文末链接)。
本阶段涉及的类:ConfigurationInfo.java、GlobleConfig.java、PropertiesFactory。
入口:com.mysql.engine.AbstractEngine#init
基于数据库获取表字段信息
上文已获取到目标数据库的配置信息,本阶段即可连接数据库,通过通用SQL获取目标库的表、字段信息。
以下面的SQL为例,只需获取数据库连接加上库信息,即可获取所有的表名
SELECTtable_name FROMinformation_schema.TABLES WHEREtable_schema = "school-miao-demo" # 库名AND table_type = "base table";# 响应# schools复制代码同理,通过通用SQL也可以获取到指定数据表的所有字段及其类型:
SELECTcolumn_name,data_type,column_comment,numeric_precision,numeric_scale,character_maximum_length,is_nullable nullable FROMinformation_schema.COLUMNS WHEREtable_name = 'schools' # 表明AND table_schema = 'school-miao-demo'; # 库名# 结果为# column_name data_type# sname varchar复制代码得到表字段的类型后存储至配置中心即可,其中的关键一点在于需要注意数据类型的映射,比如varchar映射String,int映射Integer等等,同时把表字段通过字符串处理工具类转化为驼峰类型(固定类型)的展示方式,例如:s_id => sid,这一点上需要注意数据库字段的设计规范。
基于模板生成文件
本项目中最关键的一点即在于此,如果想要实现可配置化代码生成器,一定有一个前提即:配置本身,回忆我们在多年前初学JSP的时候,有没有觉得JSTL表达式还蛮神奇的,它可以将Java语言和HTML语言完美的混合在一起,虽然现在我们已不再使用它,但是这种模板化的思想和工作方式,恰好可以用在此处。
通过调研发现,在类似JSP的技术中,FreeMarker完美符合我们的预期,其中它的:
freemarker.template.Template#process(java.lang.Object, java.io.Writer)
方法,可以通过指定模板文件(FTL)、Java实体、目标文件的方式,来帮助我们实现内容的填充,使用方法类似JSTL,如下:
package ${packageName}.entity;import java.io.Serializable;import lombok.Data;import java.util.Date;import java.util.List;/** * ${classInfo.classComment} * @author ${authorName} ${.now?string('yyyy-MM-dd')} */@Datapublic class ${classInfo.className} implements Serializable { private static final long serialVersionUID = 1L;<#if classInfo.fieldList?exists && classInfo.fieldList?size gt 0><#list classInfo.fieldList as fieldItem > /** * ${fieldItem.columnName} ${fieldItem.fieldComment} */ private ${fieldItem.fieldClass} ${fieldItem.fieldName};</#list></#if>}复制代码上述代码中的packageName、classInfo.classComment、classInfo.className等等即为我们之前获取的配置信息。
<#list> 标签即可FreeMarker中的迭代标签,我们只需按照自己的需要,将变化的部分留出来即可。
实现拔插接口
按照上文中的进度,我们在持有模板的情况下(当然还需要配置模板目录),已经可以实现项目的生成,但如何实现高扩展,拔插式接口呢?
思路有下面几个:
基于SPI的方式向外提供接口基于反射获取指定类的实现类不了解什么是SPI的小伙伴可以看这篇文章:「一探究竟」Java SPI机制。
因为本项目并不想让其他项目依赖,因此采用方式二,借用大名鼎鼎的reflections包来实现类扫描。
Maven官方地址:mvnrepository.com/artifact/or…
核心代码如下:
public final class CustomEngineImpl { /*** * 扫描全包获取 实现CustomEngine接口的类 */ private static Set<Class<? extends CustomEngine>> toDos () { Reflections reflections = new Reflections(new ConfigurationBuilder() .setUrls(ClasspathHelper.forPackage("")) .filterInputsBy(input -> { assert input != null; return input.endsWith(".class"); })); return reflections.getSubTypesOf(CustomEngine.class); } public static void handleCustom() { Set<Class<? extends CustomEngine>> classes = toDos(); for (Class<? extends CustomEngine> aClass : classes) { // 基于配置项检测是否需要启用自定义实现类 if("*;".equals(GlobleConfig.getGlobleConfig().getCustomHandleInclude()) || GlobleConfig.getGlobleConfig().getCustomHandleIncludeMap().containsKey(aClass.getSimpleName())) { try { // 基于反射构建对象 - 调用handle方法 CustomEngine engine = aClass.newInstance(); engine.handle(GlobleConfig.getGlobleConfig(), ClassInfoFactory.getClassInfoList()); } catch (InstantiationException | IllegalAccessException e) { e.printStackTrace(); } } } }}复制代码例如,我们实现数据库的文档模板类,即可非常完美的实现拓展效果,模板如下:
# 基础介绍| 说明 | 内容 || :------- | ---- || 项目名 | ${config.projectName} || 作者 | ${config.authorName} || 数据库IP | ${config.ip} || 数据库名 | ${config.dataBase} |<#if classInfos?exists && classInfos?size gt 0><#list classInfos as classInfo >## ${classInfo.tableName}表结构说明| 代码字段名 | 字段名 | 数据类型(代码) | 数据类型 | 长度 | NullAble | 注释 || :--------- | ------ | ---------------- | -------- | ---- | -------------- | ---- |<#list classInfo.fieldList as fieldItem >| ${fieldItem.fieldName} | ${fieldItem.columnName} | ${fieldItem.fieldClass} | ${fieldItem.dataType} | ${fieldItem.maxLength} | ${fieldItem.nullAble} | ${fieldItem.fieldComment} |</#list></#list></#if>复制代码效果展示:
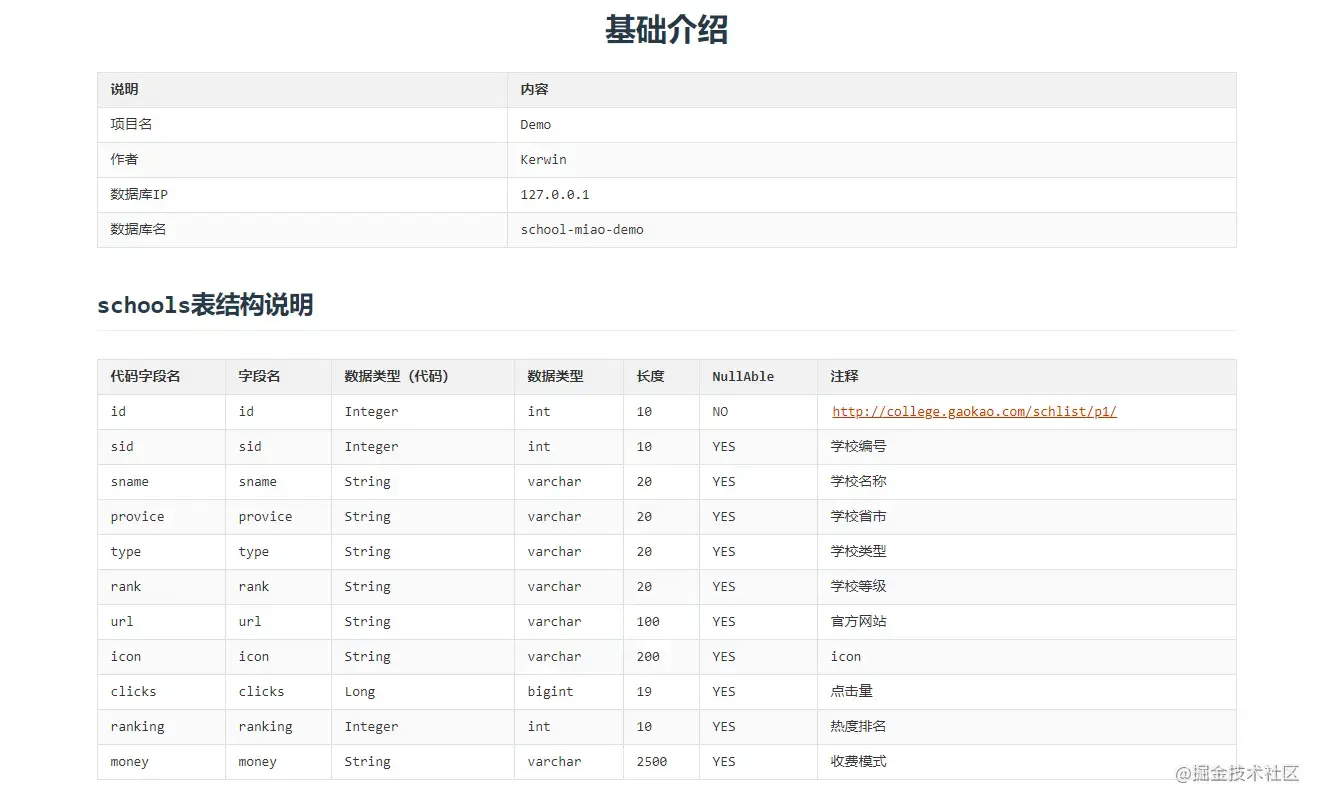
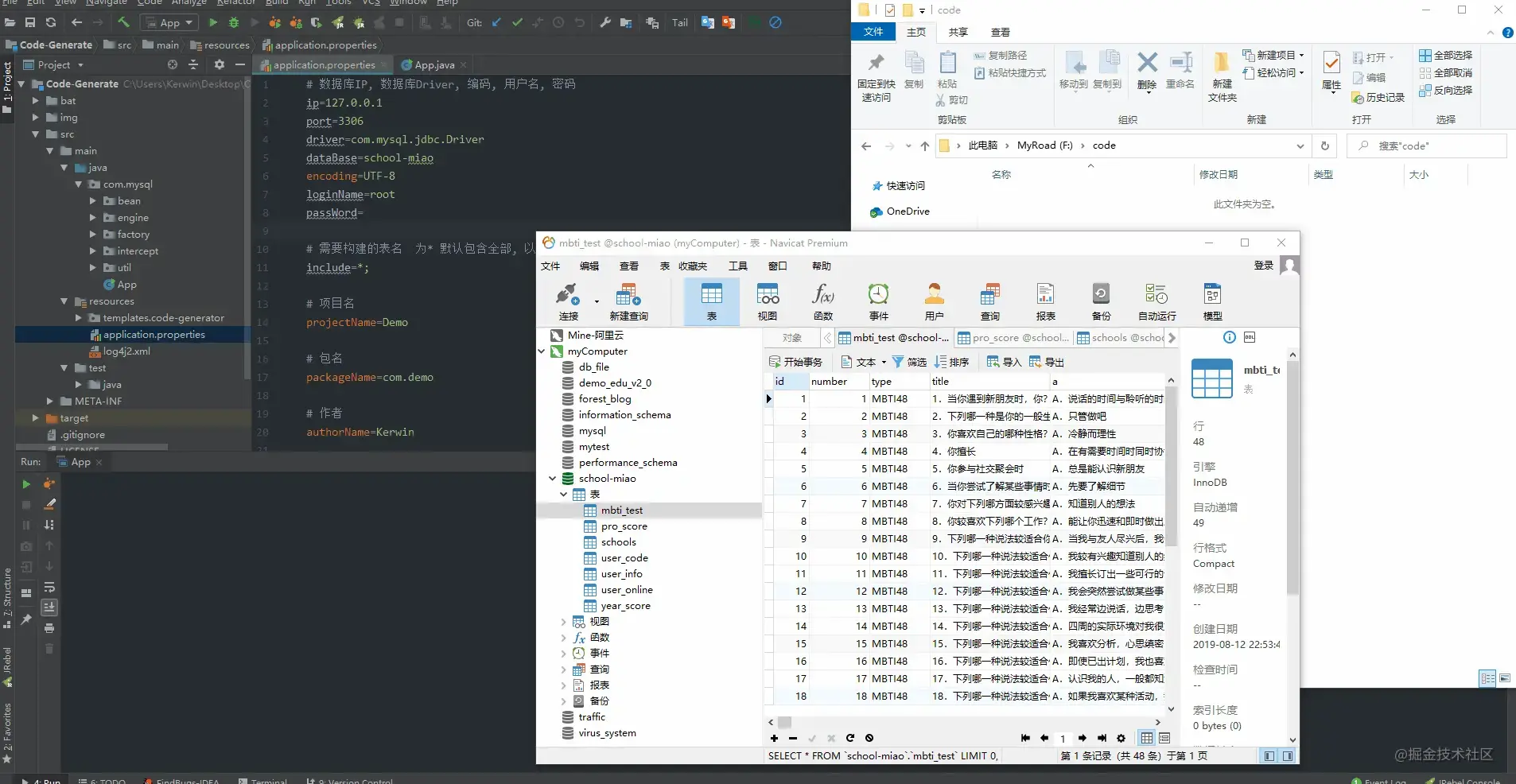
成果检验
说了这么多,直接来看看效果吧~
一点探索:FreeMarker 如何实现的模板解析
本项目中最关键的一点就在于FreeMarker帮助我们实现了模板内容生成文件这一最复杂的步骤,其特点和JSP的JSTL语法极为相似,现在咱们就来一起研究研究它的底层实现原理,看看有没有什么值得借鉴的地方。
从易到难来看,如果让你来实现一般仅支持文本替换的JSTL语法,你会觉得困难吗?在我看来并不困难,我们只需要规定特殊的语法,触发我们的解析规则,然后将内部字段与我们存储的实体对象进行映射,再输出即可,例如:
// 我是一个测试#{demo.name}// 按行读取,触发#{}正则匹配时,将 demo.name 替换为 Map/其他数据结构的值即可。复制代码简单的解决了,再想想麻烦的,下面这种需要如何解决呢?
<#list classInfo.fieldList as fieldItem> /** * ${fieldItem.columnName} ${fieldItem.fieldComment} */ private ${fieldItem.fieldClass} ${fieldItem.fieldName};</#list>复制代码假设,<#list> 标签如果前后不一致则出错(有前面的标签,没有后面的标签),你会想到什么?
是不是和LeeCode算法中的生成括号一题有点相似,在那道题中要求,生成的 () 左右括号必须一一匹配,那我们在做这道题时必然会想到使用栈这种数据结构。再来看FreeMarker是如何实现的,代码如下:
/** * freemarker.core.Environment#visit(freemarker.core.TemplateElement) * "Visit" the template element. */void visit(TemplateElement element) throws IOException, TemplateException { // 临时数组,存储数据 pushElement(element); try { // 构建子元素集 TemplateElement[] templateElementsToVisit = element.accept(this); // 遍历子元素 if (templateElementsToVisit != null) { for (TemplateElement el : templateElementsToVisit) { if (el == null) { break; // Skip unused trailing buffer capacity } // 递归遍历 visit(el); } } } catch (TemplateException te) { handleTemplateException(te); } finally { // 移出数据 popElement(); }}复制代码它的设计思想非常简单,即将文本按行分割,然后逐行递归遍历,DEBUG示意图如下,下文中元素节点共计13行,开始按行进行逐行遍历。
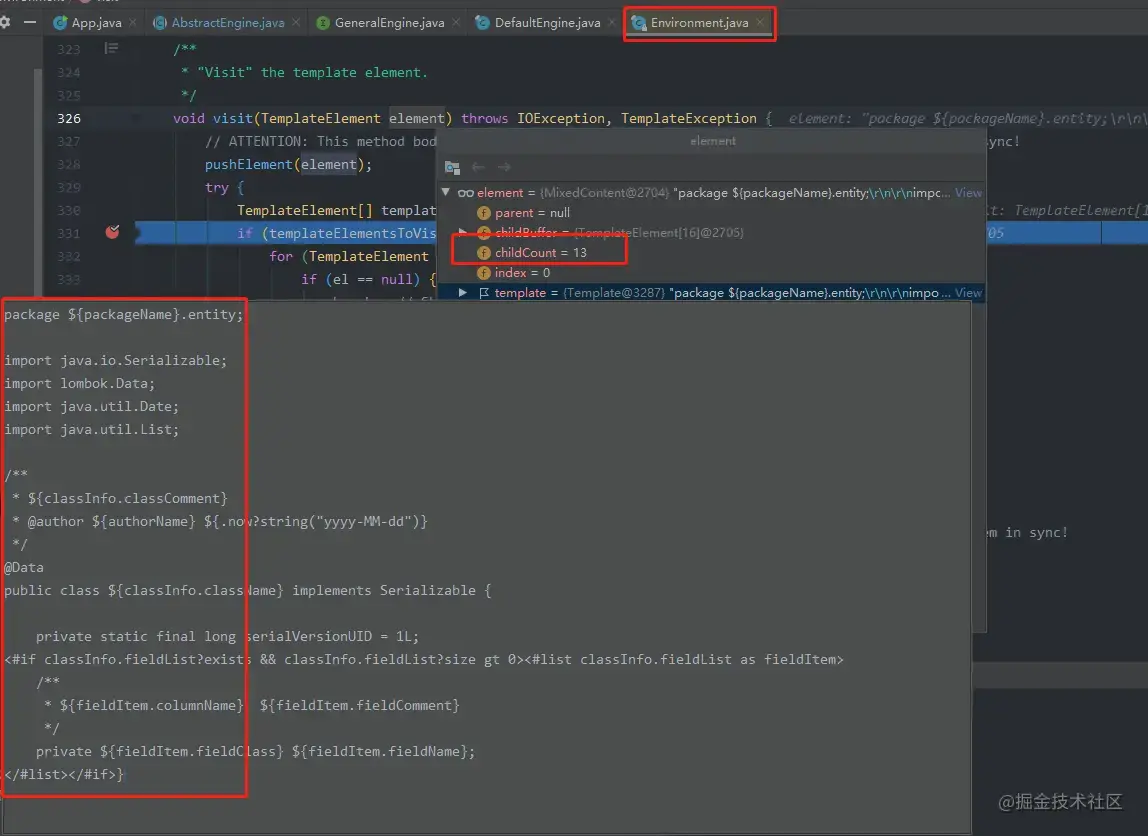
当涉及到文中的迭代一项的父级,即<#if>标签时,已经将其内部的所有元素集合获取,然后基于特定的处理类:freemarker.core.IteratorBlock#acceptWithResult 一次性全部粗合理完成,DEBUG图如下:

至此就完成了迭代器的处理方式,此中的关键就在于如何识别出哪些代码属于迭代,是不是和生成括号有异曲同工之妙~
总结
本项目主要的核心即两个通过mysql内置的表字段查询配合FreeMaker模板,构建具有一定规律性,通用的代码内容,技术要点包括但不限于:
FreeMakermybatis 原生XML,包含增,批量增,删,批量删,多条件分页查询,列表查询,单一查询,单一数据修改等logback日志SpringBoot拔插式拦截器(基于org.reflections实现),支持扫描指定接口项目源码(支持基础模块、HTML模块、数据库文档模块):GitHub地址
作为程序员,合理偷懒,天经地义!
作者:Kerwin_链接:https://juejin.cn/post/7010560347824193543来源:掘金著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。