








“搜索”在这个数据信息冗杂的时代里,充当着人们信息的筛选器,人们通过使用搜索功能,可以获得自己想要的内容,屏蔽掉无用的信息。对于商家来说,理论上,搜索功能在一定程度上可以增加长尾信息的曝光度。但是,总所周知,搜索引擎的排序规则实际上饱含水分,竞价排名的规则下,长尾信息的曝光可能就打水漂了。所以,无论是C端还是B端的产品经理,深谙搜索引擎规则,并学会利用好搜索引擎都非常重要。

一、 初识搜索引擎
1. 搜索引擎简史
提及搜索引擎,大家脑海中就会浮现起国内的百度和国外的Google,我们想要查找什么资料,直接在搜索框中输入关键字,点击搜索按钮,之后就会展现搜索结果。

其实这只是搜索引擎的一部分,我们使用微博搜索某个明星,使用淘宝搜索商品,使用豆瓣搜索一本书,都是搜索引擎。这些搜索引擎因为太常用,我们反而没有意识到。
搜索引擎本质上是一种信息获取方式。
搜索引擎主要经历了:分类目录、相关性搜索、高质量搜索、个性化搜索四个阶段。
在搜索引擎诞生前,我们使用分类目录来获取信息。Yahoo!和国内hao123是分类目录的代表。当时信息相对较少,通过人工整理,把属于各个类别的高质量网站罗列出来,比如:按照财经类、新闻类、体育类、游戏类等项目进行整理,用户可以通过分类目录来查找需要的信息。
但一个页面的展示空间有限,分类目录也只能收录少数的网站,绝大多数网站都无法被收录,而那些没有被收录的信息,可能正是大家需要的。
有需求,就有商机,搜索引擎顺势而生。
最早的搜索引擎,通过查找用户输入的关键词与网页信息的匹配程度,也就是计算两者的相关性,展示网页列表,至于如何计算匹配程度,会在后文讲解。
相比分类目录,这种方式可以收录大量的网页,并按照用户查询的关键词和网页内容的匹配程度进行排序。
但这种方式有个巨大的问题:只考虑了相关性,没有考虑网页的质量。网页可以通过大量罗列跟内容无关的关键词,来提高与关键词的相关性。
比如:一家做教育的网站,可能会罗列明星、宠物、新闻甚至色情等高流量词语,这种“强行蹭流量”的方式,造成的后果就是搜索结果质量并不好。
解决这个问题的是Google,Google假设网页的链接越多,网站质量越高。利用网页之间的链接数量来确定网页质量,一个网页的链接数量越多,说明在网页在整个互联网中质量越高,Google的核心算法,也会在后文讲述。
发展到现在,搜索引擎不仅需要解决相关性和质量的问题,还要更多考虑用户的真实需求,比如:同样输入“苹果”,年轻人可能想的是手机,另外一些人想到的是水果。这就需要更加复杂的算法和程序了。
二、什么是好的搜索引擎
从分类目录、相关性搜索、高质量搜索、个性化搜索,我们可以从搜索引擎的发展阶段看出,搜索引擎越来越复杂,用户体验也更好了。
那么,如果判断一个搜索引擎好不好呢?
主要有三个评价标准:
1. 好的搜索引擎要快
速度是用户对搜索引擎的第一个印象。
当用户搜索一件商品,几十秒还没有搜索到,他可能去干其他事情了,就直接放弃购买了!商用搜索引擎的查询速度要达到毫秒级,一眨眼的功夫,搜索结果就出来了,用户体验就很好。
影响搜索速度的因素有很多,索引是最关键的因素之一,关于索引,会在下一节详细介绍。
2. 要查的准
当用户翻了3页还找不到想要的内容,干脆就不找了。
影响查询准确率的因素同样有很多,主要有下面这三个:
搜索引擎本身存储的信息要全,对于百度等商用搜索引擎,这就要求爬虫能够爬取全网内容。关键词和网页内容的相关性要高,用户搜索手机,结果有很多单反相机,就不太好了。网页信息质量要高,Google发明的PageRank算法很巧妙地解决了这个问题。3. 搜索引擎要具有稳定性
这也是用户对大多数产品的要求,给用户一个合理的预期,用户才能够信任这款产品,三天两头不能用了,体验就差极了。
搜索引擎是怎么工作的?
那么,搜索引擎到底是如何工作的呢?
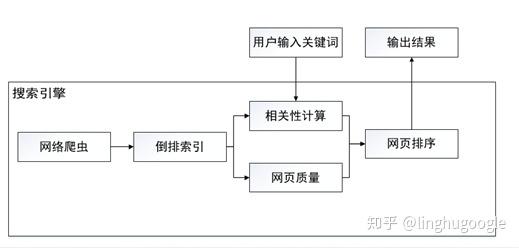
一个最基本的搜索引擎主要分为:信息获取、信息处理、信息展示三个模块。
巧妇难为无米之炊,信息获取是整个系统的基石。对商用搜索引擎而言,要求爬虫能够爬取全网内容,关于爬虫,我们再上一章已经介绍过了,这里就不再赘述。对网站内部搜索引擎而言,也需要把信息汇总起来,比如:电商平台,就需要把所有的产品信息存储到一起。
信息处理主要是对原始数据清洗,存入数据库,这里最重要的一个环节就是构建索引,相当于给每一个内容添加目录,便于查找。
信息展示指搜索引擎根据用户的查询词(query)来进行数据库检索,将结果展示给用户,主要涉及到用户查询内容与网页内容的相关性分析、网页质量评价等技术。
虽然搜索引擎具体实现方式有差异,但所有的搜索服务都可以在这三个模块的基础上实现。
三、内容索引
搜索引擎为什么这么快?
好的搜索引擎的评价标准之一就是要快,那么搜索引擎是如何实现的呢?
在开始讲解之前,我们可以考虑另外一个相似的问题:如何在图书馆找到一本书?
最笨的方法是一个书架、一个书架地找,这会花费大量的时间。
聪明一些的方式是通过索书号,快速找到所在书架,进而找到这本书。
搜索引擎中的索引就相当于图书馆里每本书的索书号,通过索引,可以快速找到需要的信息。
索引到底长啥样?
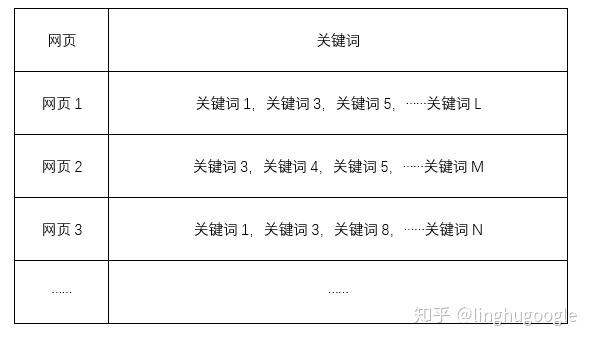
以网页搜索引擎为例:下面这张图是一个简单的索引系统(更准确的说法是倒排索引,至于为什么是倒排,这里先卖个小关子,后面会讲到)。
左边是关键词,右边是这个关键词出现在哪个网页中,一个关键词可能同时出现在很多网页中,所以是一对多的关系。
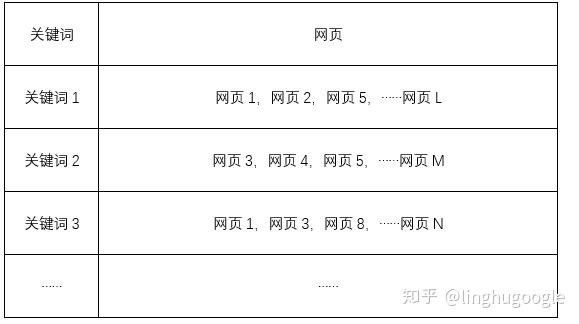
与图书馆索引不同是:一个图书馆再大,藏书毕竟还有有限的,图书管理员可以手工给每个图书建立索书号。但搜索引擎存储的数据都是以亿计算的,不可能手工建立索引,只能借助一些技术手段。
从上面的表格我们可以看出,构建索引主要有两个过程:查找关键词,把关键词和网页对应起来。
关键词
构建索引的前提是提取出关键词,那么给定一个文本(也就是网页的文字内容),如何获取里面的关键词呢?
主要有两步:首先是获得文本里出现的所有词语,也叫做分词,之后再从中筛选一些作为关键词。
第一步,分词。
如果是一句英文,“Marry had a little lamb”,每个词都是用空格分开的,里面有“marry”、“had”、“a”’、“little”、“lamb”这五个单词,但中文“玛丽有一只小绵羊”,因为没有分隔符(比如:空格)把每个词语分开,就有些麻烦了。
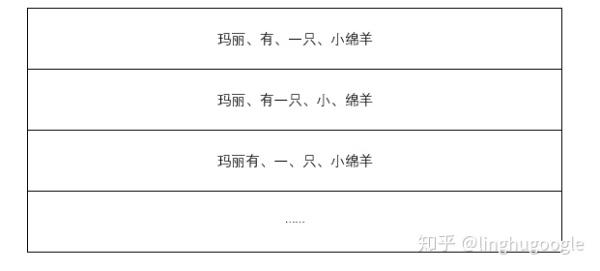
最容易想到的分词方法就是查字典,把句子从左到右看一遍(程序员的说法叫做遍历),每个词语如果在字典中出现过就标记出来。
拿“玛丽有一只小绵羊”举例,比如:“玛丽”这个词在字典中出现过,就把“玛丽”作为一个词语,“有”在词典中出现过,就把“有”作为一个词语,就这样一直做下去,最后可以分为“玛丽、有、一只、小绵羊”。
这种最简单的方式可以解决一部分问题,但也有很大的问题,比如是“小”“绵羊”还是作为整体的“小绵羊”呢?
程序员使用统计学解决这个问题:
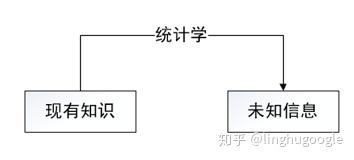
从形式上看,词是字的组合,两个字组合在一起可能是一个词语,也可能不是,如果是词语的可能性(概率)大一些,我们就倾向于认为它们可以组成词语。
这就像:天气预报说明天下雨的概率70%,不下雨的概率30%,我们就倾向于认为明天下雨。“小绵羊”一起出现的概率是70%,分开出现的概率是30%,我们就倾向于认为“小绵羊”是一个词语。
那么,如何计算相邻的字组成词语的概率呢?
我们可以对语料库中相邻出现的各个字的组合的次数进行统计,计算所有的字相邻出现的频率,当语料库足够大时,出现的频率越高,对应的概率也就越高。
我们可以计算一个句子中所有组合出现的概率,产生最大的概率组合,就是分词的结果。
比如:“玛丽、有、一只、小绵羊”每一个词语出现的概率就大于“玛丽、有一、只、小、绵羊”等其他组合出现的概率,那么,我们就认为这个句子就按照“玛丽、有、一只、小绵羊”划分。
第二步,获得关键词。
对所有的文本分词之后会发现,“的”、“了”、“吗”、“也许”等没有很强实际意义的功能词有很多,相比之下“产品经理”、“搜索引擎”等词语更加具有实际意义的反而较少,后者更应该作为关键词。
于是,我们使用把所有这些功能词存起来,作为停用词(stop word),如果一个词语出现在停用词中,就不能作为关键词。于是,我们就从分词结果中,获得了关键词。
下面是一个简单的停用词表,可能看出,基本都是我们经常使用的、没有很强实际意义的词语。
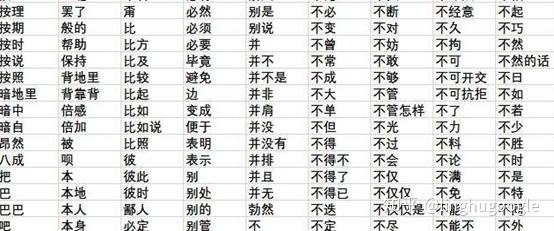
中文分词是几乎所有中文自然语言处理(Natural Language Processing)的基础,所以学术界和产业界对中文分词的技术研究已经很深入了,有高质量的商用分词库,也有像jieba这样的开源中文分词库,可以免费使用。
通过提取每个网页的关键词,最终每个网页和关键词的对应关系如下:
需要注意的是:获取关键词不仅用在网页处理,而且也用在输入搜索框中。当我们搜索一句中文的时候,搜索引擎内部会进行分词、去掉停用词,获得关键词,之后再进行后续处理。
倒排索引
现在,我们已经建立好了索引,对于每一个网页,我们找到了出现的所有关键词。
当用户查询时,我们从头到尾,对每一篇文件扫描一遍,看哪个网页出现了用户查询的关键词,就把这个文件作为搜索结果。
但问题是:动辄上亿的网页数量,从头到尾扫描一次就要花好长时间,根本无法满足正常的需求,更别说快速响应了。
那我们能不能把关键词放前面,网页放后面?
这样,当我们检索的关键词的时候,不需要遍历整个系统,只用查找对应的几个关键词,就可以找到需要的网页了!
对计算机而言,直接寻找关键词所在位置的信息,所需的时间非常短,完全可以满足搜索的需要。
比如:用户搜索“关键词1”,那么搜索引擎只需要找到“关键词1”,就可以会直接找到“网页1,网页2,网页5,……网页L”。
用户搜索“关键词1+关键词2”,那么搜索引擎需要找到“网页1,网页2,网页5,……网页L”,“网页3,网页4,网页5,……网页M”,找到同时出现的“网页3、网页5,……”。这样就大大加快了呈现排名的速度。

把“文件-关键词”这种结构颠倒一下,“关键词-文件”,就是倒排索引名字的由来。
更进一步,倒排索引中不仅仅记录了包含网页的ID,还会记录关键词出现的频率(term frequency)、每个关键词对应的文档频率(inverse document frequency),以及关键词出现在文件中的位置等信息,这些信息可以直接用在搜索结果排序上。
四、搜索结果排序
至此,我们通过爬虫实现了信息获取、通过倒排索引实现了信息处理,接下来就是如何把这些信息展示给用户,其中最关键的是如何排序。
对电商而言,用户可以选择按照销量、信用、价格甚至综合排序,当然, 排序中也会穿插一些推广。
对通用的搜索引擎而言,比如:百度,没有销量、评分这些选项,主要根据网页与搜索关键词的相关性、网页质量等排序。
TF-IDF模型
如何确定网页与关键词的到底有多大的相关性?
如果一个网页中关键词的出现很多次的话,我们通常会认为这个网页与搜索的关键词更匹配,搜索结果应该更靠前。
我们用词频(Term Frequency, TF)表示关键词在一篇文章中出现的频率,代表网页和关键词的匹配程度。
比如:我们在百度等搜索引擎上搜索“产品经理的工作”,关键词为“产品经理”,“工作”,“的”作为停用词,不出现在关键词中。
在某一个网页上,总共有1000个词,其中“产品经理”出现了5次,“工作”出现了10次,“产品经理”的词频就是0.005,“工作”的词频就是0.01,两者相加,0.015就是这个网页和“产品经理的工作”的词频。
这里有一个问题,相较“产品经理”,“工作” 这个词用的更多,在所有的网页中出现的概率也很高。搜索者可能希望查找产品经理相关的信息,按照TF排序,一些出现很多次“工作”这个关键字的网站,就可能排在前面,比如:《程序员的工作》、《老板的工作》等等,逆文本频率 (Inverse Document Frequency,IDF)应运而生。
文件频率(Document Frequency)可以理解为关键词在所有网页中出现的频率,如果一个关键词在很多网页中都出现过,那么它的文件频率就很高。反之亦然,比如:“工作”的DF就高于“产品经理”。
文件频率越高,这个词就越通用,有效的信息就越少,重要性应该更低。于是,我们把文件频率取个倒数,就形成了逆文本频率。
二八定律在这里同样适用,20%的常用词占用了80%的篇幅,大多数关键词出现的频率都很低,这就造成了文件频率很小,而逆文本频率很大,不便于处理。于是我们取对数,便于计算(当然,这里也有其他数学和信息论上的考虑)。
把词频(TF)、逆文档频率 (IDF)相乘,就是大名鼎鼎的TF-IDF模型了。
一个关键词在一个网页中出现的频率越高,这个关键词越重要,排名越靠前;在所有网页中出现的频率越高,这个关键词告诉我们的信息越少,排名应该更靠后。
TF-IDF模型帮助我们解决了关键词与网页相关性的计算,仅仅使用TF-IDF模型,也可以搭建出效果不错的搜索引擎。
当然,商用搜索引擎在TF-IDF的基础上,进行的一定的改进,比如:出现在文章开头和结尾的关键词更加重要,会根据词出现的位置调整相关度。但还是基于TF-IDF模型的调整。
大名鼎鼎的PageRank
搜索结果排序,仅仅考虑相关性,搜索的结果并不是很好。总有某些网页来回地倒腾某些关键词,使自己的搜索排名靠前(当然,部分原因也来自某些搜索引擎更加喜欢推荐自家的东西,这个就不属于技术问题了)。
引入网页质量,可以解决这个问题。排序的时候,不仅仅考虑相关性,还要考虑网页质量的高低,把质量高的网页放在前面,质量低的放在后面。
那么,如何判断网页质量呢?
解决这个问题的是两位Google的创始人。搜索引擎诞生之初,还是美国斯坦福大学研究生的佩奇 (Larry Page) 和布林 (Sergey Brin) 开始了对网页排序问题的研究。
他们的借鉴了学术界评判学术论文重要性的通用方法,看论文的引用次数,引用的次数越高,论文的质量也就越高。他们想到网页的重要性也可以根据这种方法来评价。
佩奇和布林使用PageRank值表示每个网页的质量,其核心思想其实非常简单,只有两条:
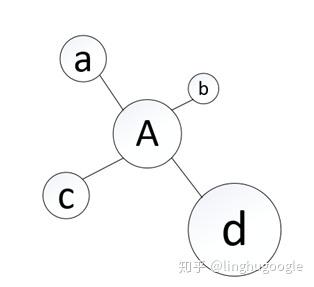
如果一个网页有越多的链接指向它,说明这个网页质量越高,PageRank值越高,排名应该越靠前;排名靠前的网页应该有更大的表决权,当一个网页被排名靠前的网页链接时,PageRank值也越高,排名也更靠前。我们做一个类比:
有一个程序员,如果公司的人都夸他编程技术高,那么我们认为他编程技术高;如果他被公司的CTO赏识,我们基本可以确定他的编程水平确实牛。比如:下面这张图(专业术语叫做拓扑图),每一个节点都是一个网页,每条线都是两个网站之间的链接。
链接越多,说明网站质量越高,相应的PageRank值就越高。
这里有个问题:“当一个网页被排名靠前的网页链接时,其排名也应靠前”,一个网页的排名的过程需要用到排名的结果,这就变成了“先有鸡还是先有蛋”的问题了。
Google的两位创始人用数学解决了这个问题:
最开始的时候,假设搜索的网页具有相同的PageRank值;根据初始值,开始第一轮的计算,按照链接数量和每个网页的PageRank值重新计算每一个网页的PageRank值;按照上一轮的结果,按照链接数量和每个网页的PageRank值重新计算每一个网页的PageRank值……
这样计算下去,直至每个网页的PageRank值基本稳定。
你可能会好奇,这样要计算多少次?
佩奇在论文中指出:对网络中的3.22亿个链接进行递归计算,发现进行52次计算后可获得收敛稳定的PageRank值。
当然,PageRank实际运行起来比这个更加复杂,上亿个网页的PageRank值计算量非常大,一个服务器根本无法完成,需要多台服务器实现分布式计算了。为此,Google甚至开发出了并行计算工具MapReduce来实现PageRank的计算!
除了巨大的计算量,PageRank同样要面对作弊的问题。
开头我们谈到TF-DIF的弊端的时候讲到:总有某些网页来回地倒腾某些关键词,使自己的搜索排名靠前。
同样的,针对PageRank,也总有些网页来回地倒腾链接,使自己的搜索排名靠前。这就需要更多的算法,来识别这些“作弊”行为,我们在搜索引擎反作弊一节再来细讲。
其他排序方式
至此,使用TF-IDF计算网页与搜索内容的相关性,使用PageRank计算网页质量,可以很好地实现网页排序,一个基本的搜索引擎就搭建完成了。
商用搜索引擎在此基础上,还衍生了出其他的排名方式。
竞价排名:
比较著名的是百度推出的竞价排名(其实最开始做竞价排名的不是百度,但百度做得太“成功”,也至于大家都认为是百度发明了竞价排名),竞价排名按照按网站出价高低决定排名先后。
这种排名方式最大的优点是:可以帮助搜索引擎公司盈利。
最大的弊端是:无法保证出价高的网页的质量高,在医疗等特殊领域,有时甚至相反。
随着用户数据的积累,关键词和对应用户点击网页的行为数据也被搜索引擎记录下来了,搜索引擎可以根据用户的操作,不断改进自己的引擎。
时至今日,商用搜索引擎的底层技术都差不了太多,用户数据记录成为了竞争的关键因素,这也是百度得以在国内的搜索引擎市场独占鳌头的重要原因——用户越多,搜索越准确,搜索越准确,用户越多!
站内搜索:
百度、Google等通用搜索引擎要做很多工作,相比之下,站内搜索就简单很多——数据量少、也基本都是整理过的结构化数据,比如:豆瓣读书,搜索的时候直接检索自己的数据库就可以了。
虽然站内搜索的技术与通用搜索引擎有很多不一样的地方,但构建索引、相关性计算、质量计算、排序等流程基本一致。对于站内搜索的需求,同样存在开源的解决方案。
业界两个最流行的开源搜索引擎——Solr和ElasticSearch,它们运行速度快、效果好、可靠性高、可扩展,最关键的是免费,足以满足一般的商业需求。
对大多数公司而言,直接使用开源搜索引擎就可以了,不用重新造轮子,甚至,这些开源的解决方案比自己从头搭建的还更加稳定可靠。
五、 SEO与搜索引擎反作弊
SEO
搜索引擎结果排名影响流量,流量影响利润,有利润的地方就有“商机”,SEO就是针对搜索引擎排名的“商机”。
SEO(Search Engine Optimization)中文为搜索引擎优化——即利用搜索引擎的规则提高网站在搜索结果的排名。
SEO优化通常有两种方式:一种是网站内部优化,一种是外部优化。
内部优化主要是优化网页内容,比如:提高关键词的数量,优化网页内部标签等。更有甚者,一些网页会使用非常小的字重复关键词,或者使用跟背景相同的颜色重复一些高流量词语,以实现较高的排名。
外部优化主要优化链接,比如:添加友情链接、论坛、贴吧、知道、百科等,这就产生了买卖链接的生意。
可以看出:SEO的优化基本针对的就是TF-IDF和PageRank的排序方式,“投其所好”提高自己的排名。
搜索引擎反作弊
从用户的角度讲:高质量的、相关的信息才是真正需要的。
一些网页凭借SEO优化获得较高排名,本身可能质量不高、相关性也比较弱,这对那些老老实实提供优质内容的网站也是不公平的。
长此以往,可能就会产生“劣币驱逐良币”,搜索引擎搜索到的优质内容不断减少。
从这个角度看,SEO就是针对搜索引擎的作弊,搜索引擎公司也不希望这样的事情发生——搜索不到需要的信息,用户也许直接就跑了!
Google诞生初期,就一直面对作弊与反作弊的问题。
在2001年,敏感的站主和SEO优化者发现:有些网站的Google排名一夜之间就一落千里,有的网站排名则大幅上升,这个现象几乎是每月一次。
后来,人们才知道,Google定期地更新它的反作弊算法,提高搜索质量,这给人的感觉就像跳舞一样,因此被SEO称为Google Dance。
那么,Google是如何反作弊的呢?
虽然各种作弊行为的方式各不相同,但目标一致,都是为了获得更高的排名,大体上还是有一定规律的。根据这些规律,搜索引擎常用的反作弊方式有两类:根据作弊特征的主动出击,建立“黑白名单”的被动防御。
首先,搜索引擎会根据作弊网站的特征主动出击。
就像我们总是能从人群中一眼看到长得最特殊的人一样,一个出现大量重复关键词网页、一个出现大量链接的网页和一个普通的网页,在搜索引擎看来是很不一样的。
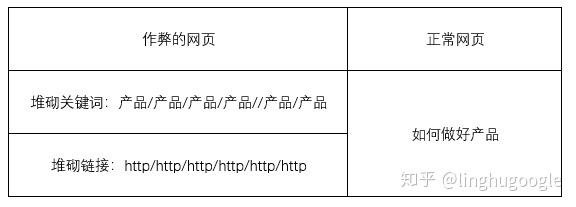
通过计算网页的关键词数量特征、链接数量特征,可以很快发现那些“出格”的网站,搜索引擎就可以凭此调整排名。(前文所述的Google Dance就是根据作弊网站链接异常实现反作弊的。)
其次,搜索引擎也会建立“黑白名单”,作为防御手段。
搜索引擎会根据网站内容的质量、品牌、权威程度等信息建立一个白名单,比如:政府网站、一些大公司网站就在白名单中,这些网站的质量较高,排名也靠前,白名单链接的网站质量一般也会较高。
与之对应的是黑名单,主要包括那些作弊严重的网站——比如:堆叠关键词、买卖链接的网站。如果同一个网站链向了多个黑名单中的网站,就可以把其认定为作弊的网站,降低排名。
猫鼠游戏
《猫鼠游戏》梦工厂出品的一部电影,根据真实经历改编,讲述了FBI探员与擅长伪造文件的罪犯之间进行一场场猫抓老鼠的故事。在搜索引擎中,也同样存在这样的猫鼠游戏。
为什么电商网站商品名称这么长?为什么会好评返现?差评有偿删除?为什么有些评价很高的宾馆/餐厅,实际却脏乱差?为什么电影评价网站经常会因为刷好评/差评进入舆论中心?为什么微博等社交媒体会有令人咂舌的阅读、点赞和转发数量?网站和商品本身的相关性和质量很难客观量化,根据关键词、销量、评价、点击、阅读量等较为客观的指标生成排序结果,甚至决定是否进入热搜榜、热销榜,仍然是当前搜索引擎的工作原理。
搜索引擎面对这些行为,也不断进化出新的应对策略。
面对刷单行为,平台经历了睁一只眼闭一只眼的无可奈何,到物流追踪、下单用户身份判断的演变,刷单成本也随之急剧上升,刷单行为虽然没有被杜绝,但也大幅下降。
面对阅读量、点击造假等方式,社交媒体也经历着从听之任之到屏蔽刷排名的转变,中间虽然有收入的降低、用户活跃度下降、大V流失的风险,但也终究要踏上这一步。
但,这场作弊与反作弊的猫鼠游戏,并没有终点。
本文由@linghu 原创发布于人人都是产品经理,未经许可,禁止转载
题图来自Unsplash, 基于CC0协议