









一、网页的检查
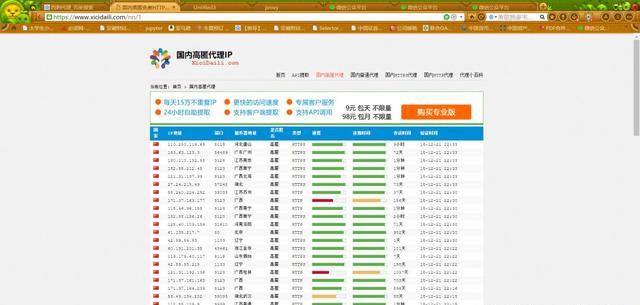
西刺代理网下的国内高匿部分,是一个很简单的get请求,唯一变化的就是url:
第一页的url为:https://www.xicidaili.com/nn/1
第二页的url为:https://www.xicidaili.com/nn/2
网页界面如下,很规则,很友好。下面开始写代码。

私信菜鸟007获取此案例源码!
# 定义一个主函数def main(): # 输入固定的参数 url = 'https://www.xicidaili.com/nn/' start_page = int(input('\n请输入起始页码:')) end_page = int(input('\n请输入结束页码:')) items = [] # 构建一个循环,用于爬取任意某页至某页 for page in range(start_page,end_page+1): print('\n第{}页开始爬取'.format(page)) # 拼接网页 url_new = url + str(page) + '/' # 请求网页,获取响应——通过构建函数:req_res 实现 response = req_res(url_new) # 解析响应——通过构建函数: parse_res 实现 items = parse_res(response,items) # 休眠5秒 time.sleep(2) print('\n第{}页结束爬取'.format(page)) # 以CSV格式保存数据 df = pd.DataFrame(items) df.to_csv('IP_data.csv',index=False,sep=',',encoding='utf-8-sig') print('*'*30) print('全部爬取结束')if __name__ == '__main__': main()2、拼接url
该步只需要一行代码,因此直接写在主函数中。
# 拼接urlurl_new = url + str(page) + '/'3、请求网页,获取响应。
主函数要尽量保持简洁,而把复杂的代码通过定义函数来实现,这里的第二步(即请求网页)和第三步(即获取响应)代码较多,这里通过建立函数:req_res来实现,由于urllib库已经介绍过,这里使用requests库来进行实现。代码如下:
# 构建请求函数,返回得到的响应def req_res(url): # 构建请求函数第一步——构建头部信息 USER_AGENT = [ "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)", "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)", ] user_agent = random.choice(USER_AGENT) headers = { 'User-Agent':user_agent } # 构建请求函数第二步——构建代理池 # 本文就是为了爬取代理池,此处略 # 发起请求,获取响应 response = requests.get(url,headers = headers).text # 返回响应 return response4、解析函数
获得响应之后,就要对响应进行解析了。这里也通过建立一个函数来实现。同样还是使用bs4.
代码如下:
# 构建解析函数,返回数据(以字典格式返回)def parse_res(response,items): soup = BS(response) # 先取出所需数据的所有存放地——<tr></tr> tr_list = soup.select('#ip_list > tr')[1:] # 通过遍历tr列表取出所需数据——这里演示都取出,实际只需要ip地址和端口 for tr in tr_list: # 获取ip地址 ip_add = tr.select('td')[1].text # 获取端口 port = tr.select('td')[2].text # 获取服务器地址 server_add = tr.select('td')[3].text.strip() # 获取是否匿名信息 anonymous_type = tr.select('td')[4].text # 获取http类型 http_type = tr.select('td')[5].text # 获取连接速度 SPEED = tr.select('td')[6] speed = SPEED.div.attrs['title'][:-1] # 获取连接时间 TIME_CO = tr.select('td')[7] time_co = TIME_CO.div.attrs['title'][:-1] # 获取存活时间 time_ar = tr.select('td')[8].text # 获取验证时间 time_pr = tr.select('td')[9].text # 将以上数据录入一个字典 item = { 'IP地址':ip_add, '端口':port, '服务器地址':server_add, '匿名信息':anonymous_type, '类型':http_type, '连接速度':speed, '连接时间':time_co, '存活时间':time_ar, '验证时间':time_pr } items.append(item) # 返回数据 return items5、保存数据
此处代码也较少,直接写在主函数中。
# 以CSV格式保存数据df = pd.DataFrame(items)df.to_csv('IP_data.csv',index=False,sep=',',encoding='utf-8-sig')6、完整代码
这样一个爬取代理IP的完整流程代码就完成了。完整代码如下:
import requestsimport pandas as pdimport randomimport timefrom bs4 import BeautifulSoup as BS# 构建请求函数,返回得到的响应def req_res(url): # 构建请求函数第一步——构建头部信息 USER_AGENT = [ "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)", "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)", "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)", "Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)", ] user_agent = random.choice(USER_AGENT) headers = { 'User-Agent':user_agent } # 构建请求函数第二步——构建代理池 # 本文就是为了爬取代理池,此处略 # 发起请求,获取响应 response = requests.get(url,headers = headers).text # 返回响应 return response# 构建解析函数,返回数据(以字典格式返回)def parse_res(response,items): soup = BS(response) # 先取出所需数据的所有存放地——<tr></tr> tr_list = soup.select('#ip_list > tr')[1:] # 通过遍历tr列表取出所需数据——这里演示都取出,实际只需要ip地址和端口 for tr in tr_list: # 获取ip地址 ip_add = tr.select('td')[1].text # 获取端口 port = tr.select('td')[2].text # 获取服务器地址 server_add = tr.select('td')[3].text.strip() # 获取是否匿名信息 anonymous_type = tr.select('td')[4].text # 获取http类型 http_type = tr.select('td')[5].text # 获取连接速度 SPEED = tr.select('td')[6] speed = SPEED.div.attrs['title'][:-1] # 获取连接时间 TIME_CO = tr.select('td')[7] time_co = TIME_CO.div.attrs['title'][:-1] # 获取存活时间 time_ar = tr.select('td')[8].text # 获取验证时间 time_pr = tr.select('td')[9].text # 将以上数据录入一个字典 item = { 'IP地址':ip_add, '端口':port, '服务器地址':server_add, '匿名信息':anonymous_type, '类型':http_type, '连接速度':speed, '连接时间':time_co, '存活时间':time_ar, '验证时间':time_pr } items.append(item) # 返回数据 return items# 定义一个主函数def main(): # 输入固定的参数 url = 'https://www.xicidaili.com/nn/' start_page = int(input('\n请输入起始页码:')) end_page = int(input('\n请输入结束页码:')) items = [] # 构建一个循环,用于爬取任意某页至某页 for page in range(start_page,end_page+1): print('\n第{}页开始爬取'.format(page)) # 拼接网页 url_new = url + str(page) + '/' # 请求网页,获取响应——通过构建函数:req_res 实现 response = req_res(url_new) # 解析响应——通过构建函数: parse_res 实现 items = parse_res(response,items) # 休眠5秒 time.sleep(2) print('\n第{}页结束爬取'.format(page)) # 以CSV格式保存数据 df = pd.DataFrame(items) df.to_csv('IP_data.csv',index=False,sep=',',encoding='utf-8-sig') print('*'*30) print('全部爬取结束')if __name__ == '__main__': main()三、爬取结果
运行上述代码,西刺代理每页显示100条IP信息,这里以爬取前50页5000条IP信息为例。结果如下:
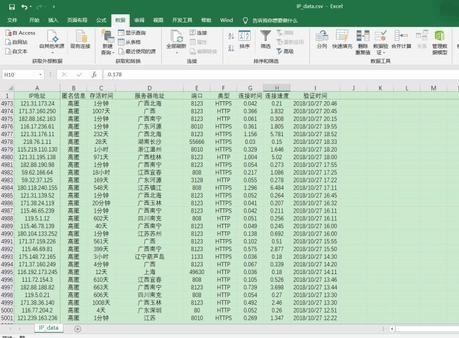
打开保存到本地的CSV文件,如下。可见5000条信息全部爬取成功。
四、IP验证
IP虽然爬取下来了,但是能不能用确是不一定的,实际上,代理IP一般都是收费的,所以免费的东西,自然没好货,不出意外的话,爬取下来的IP绝大多数是不能用的,所以需要验证下。
这里提供两种方法:
1、利用python。由于使用第二种方法,这里对第一种方法只提供想法。将爬取下来的ip使用requests库的代理方法,进行某个网页的访问,通过判断请求的响应码是否为200来判断ip是否可用(这里应该再加上个响应时间),若响应码为200则保留,否则剔除。但显然,这种方法太浪费时间。
2、利用一个叫花刺代理的软件,安装后,可直接批量检查爬取下来的IP是否可用,这里使用该软件对刚刚爬取下来的5000个IP进行检验。
首先,将刚刚爬取下来的数据通过以下代码:导出IP地址和端口信息,并保存为txt格式(该软件识别txt),代码如下。
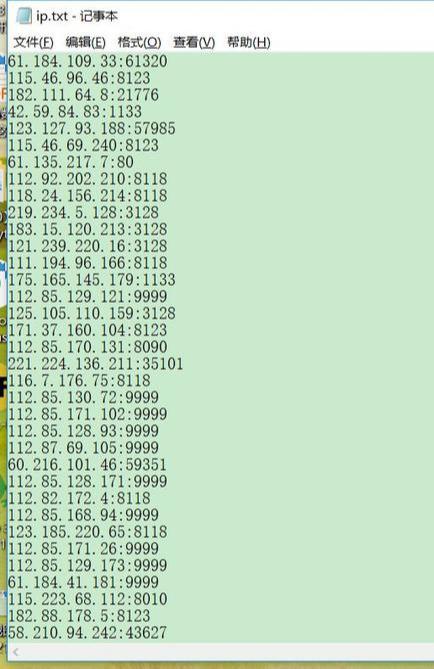
import pandas as pddata = pd.read_csv(r'C:\Users\zhche\Desktop\IP_data.csv',sep=',',encoding='utf-8-sig')lists = data.values.tolist()for list in lists: IP = list[0] port = list[4] proxy = str(IP) + ':' + str(port) with open('ip.txt','a',encoding = 'utf-8') as f: f.write(proxy+'\n')运行后,找到保存到本地的txt,如下:
然后,将该txt文件导入到花刺代理软件中,点击“验证全部”,结果如下。
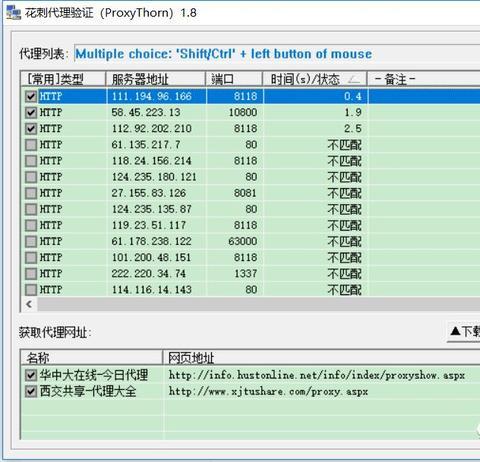
没有看错,5000个IP中只有3个能用,得出一个至理——便宜没好货。
所以平时需要用数量来代替该不足,通过抓取上万个IP来寻找几个有用的。