








从曾经的黄页到现在的算法推荐,我们虽然触达更多的信息,但是并非一定是质量更高的信息。搜索市场有着庞大的流量池,这是无法抵御的巨大诱惑。微信搜一搜的动作可能正是未来搜索引擎的发展方向,各家搜索发力,也许正在酝酿一场大战。

01
信息不对称,是这个时代的核心竞争力之一。
一件事情如果我知道,你不知道,竞争的时候你就必然会面临劣势,乃至被收割。所以信息收集和整理的能力,是这个信息爆炸的年代中最重要的能力之一。
过去我们面临的问题是信息不够多,找不到;现在我们面临的问题是垃圾信息太多,有效信息和垃圾放在一起。
很多人问我最常用的收集资料的工具是什么?
其实答案是不唯一的,因为我都是针对要收集的资料的特性,来选择匹配工具,不同工具对应的内容方向是不一样的。
如果找深度的内容,除了用学术论文搜索之外,我用的最多的是大家平时了解不多的东西,微信搜一搜。
搜一搜这个东西一直被当成微信上的一个附属功能,很多人都用过,但是未必了解,这个产品在我眼中属于是非常高效的搜索引擎。
举个例子,医疗。
我用搜一搜搜 “头痛”这个关键词, 它会告诉你,这个内容交给了某市某医院的具体哪个医生评审,而且是评审通过了的。
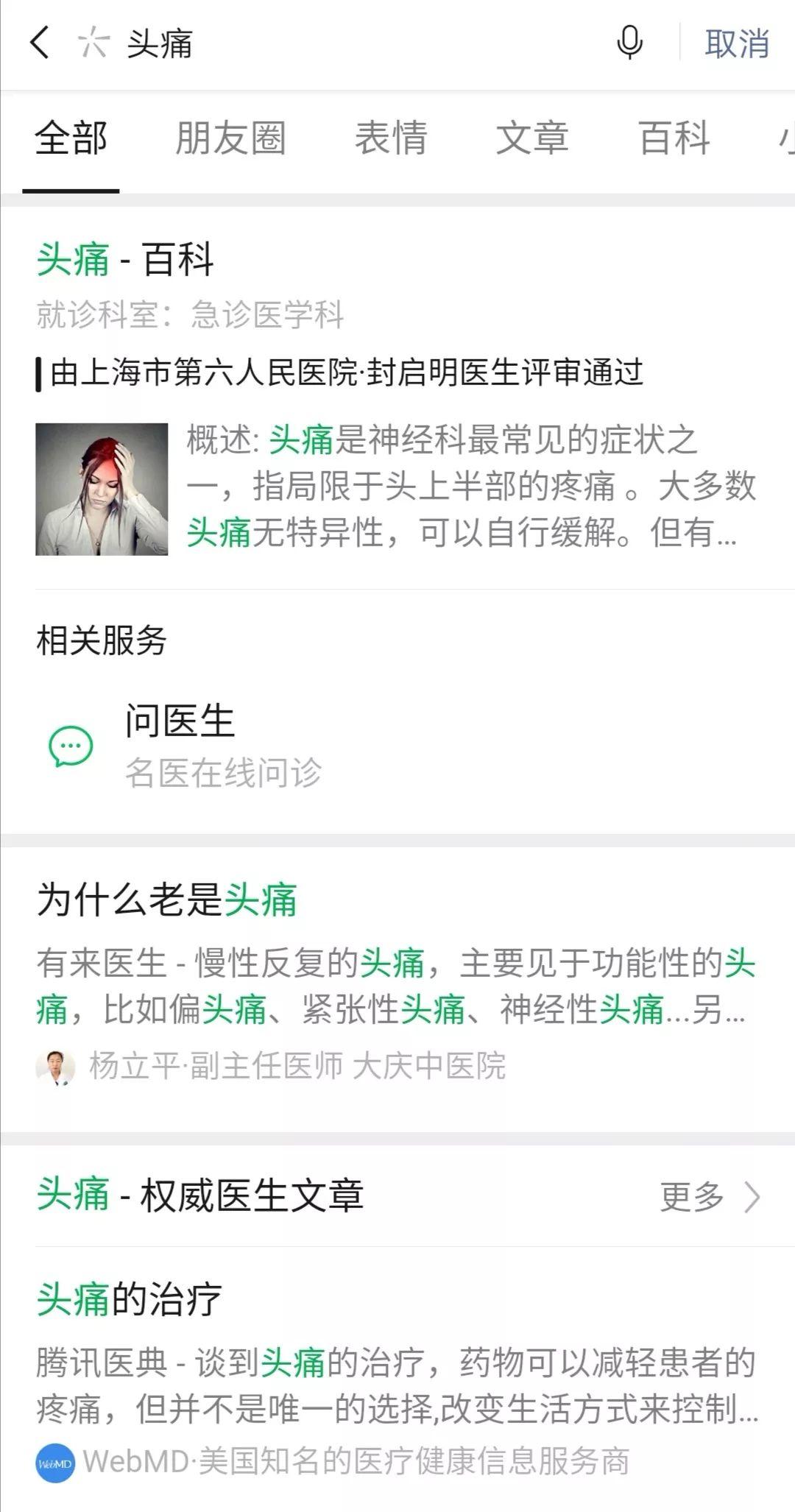
这个标注看起来就是非常小的一行字,也没有重点突出。但是从信息上讲,这个信息的来源是透明的,并且是由专业人士提供的,这就决定了这个信息大概率是可以相信的。信息检索的一大常识是,如果不知道来源和统计源,这个信息是不能被完全相信的。
把搜出来的每一条健康信息都归责到具体的人,是一件很麻烦、很复杂的事情,但是对搜索引擎很重要。
信息在可信的前提下,才有意义。
其他搜索引擎当然也可以搜健康信息,但是互联网上的共识,就是医疗“移不动”,健康信息并不推荐完全使用搜索引擎,这属于常识。
搜索引擎的信息可信度问题一直是一个毒瘤,以健康领域举例。
搜索引擎和健康联系起来,最大的隐患就是一般的搜索引擎没有能力去识别医疗信息的真假,所以既不能给正确的知识提供专业医生的背书,也不能筛掉灰产的伪医疗伪科普。
搜一搜给出的解法很简单粗暴。
1)规范化搜索结果
直接在搜索结果上给到具体医生鉴定的溯源信息,并保证相关医师可以在医院官网查询验证。这就在最大程度上,拉近了搜索引擎上获得的信息,和线下去医院里从医生那里获取的信息,二者在专业程度上的差距。
2)直接提供在线挂号服务
这就让用户不同以往的可以更便捷挂号,最终走向都是在把用户导向规范的线下医院,而不是作为一种牟利的渠道。
对于掌握了流量和内容分发的搜索引擎来说,这种自我规制和审慎非常重要,这不但是在保护用户,也是在保护自身。
严格来说,一个搜索引擎没有必要去做这样的事情,搜索引擎只提供爬虫不提供鉴别是业内公认的规则,但是做了这样的事情,其实会对用户更负责一些。
用户的搜索行为得到的结果,不仅仅是“信息”,还可以是“服务”,甚至是为用户量身定做的服务(一对一咨询医生)。
并且把这一功能集合在微信这种国民APP上,背后是微信的棋局。
使用搜索引擎激活存量资源,形成更大的协同生态。
人无我有,人有我优,人优我便利。
不仅仅是技术的问题,更是思路上的差异。
02
搜索引擎这个东西并不新鲜。
我们一般把搜索引擎分成四代,导航网站(黄页模式)是第一代,给你什么你看什么。
提供最简单的文本检索功能的是第二代,人们可以简单录入自己的需求内容,但是受限于网站的内部数据库。在第二代的后期,搜索引擎解决了内部数据库问题,使用爬虫来爬公域信息,理论上数据库是无限的。
我们最常用的,其实是第二代搜索引擎。
从第三代开始,搜索引擎开始去预测用户的意图和习惯,在搜索结果中插入高亮信息。这些信息可以是搜索引擎认为更有效的资料,也可以是广告。
前三代搜索引擎主打的都是围绕厂商端的需求。
第四代搜索引擎是基于移动互联网出现的用户中心时代,最大的特点就是搜索的私人化,依据对用户的了解,从搜索方式,搜索类型乃至搜索结果,都要往千人千面上靠。
搜索引擎的历史不算长,但是技术跃迁得非常快。
虽然给用户带来更便利的内容分发体验这个核心逻辑没有变过,但是在搜索引擎的进步过程中,也产生了很多非常有意思的技术原理,甚至和道德、法律、社会公序良俗相关。
首先是爬虫技术。
网站其实并不欢迎私人的爬虫,因为爬虫的访问量会增加网站负担,但是又无法带来真人流量。
所以现在很多网站都设置有验证码,就是为了确保访问请求都来自真人用户。
但是网站对搜索引擎的爬虫是非常欢迎并且来者不拒的,被搜索引擎爬取并且收录可以增加网站的曝光,甚至对于很多缺乏冷启动的小网站来说,被搜索引擎爬出来,就是它们唯一能得到流量的渠道了。
搜索引擎的爬虫技术其实没什么好讲的,不管技术好坏,最后都能爬出来,区别只在于爬取过程中的技术代价以及效率。
但是爬取+收录这个行为就出现了骚操作了,有一家自己不做搜索引擎但是专门给其他公司提供搜索技术的公司,叫inktomi。这是互联网早期非常重要的一家搜索引擎技术提供商,而它把自己作死的原因,是inktomi开始要求网站付费才能被受录。
实际上搜索引擎的搜索结果就是它为用户提供的商品,网站被收录,获得流量,搜索引擎收录网站,获得更多内容,本来是双赢的一件事情。
如果要求一方给钱,性质就变了。
后来的雅虎和Google就是因为免费策略而大获成功。
搜索引擎很赚钱,但过度追求金钱,最后必然会带来失败,这是搜索引擎的第一个教训。
再比如搜索结果的排名机制,也历经过非常有趣的演变。
二代搜索引擎的排名机制和爬取机制是一体的,用的都是一些信息检索模型,比如布尔模型,概率模型或者向量空间模型。
这种机制下,其实不存在排名问题,因为返还给用户的直接就是一个链接清单,里面会夹杂大量用户不关心的链接,用户必须一条条全部看完才能找到自己需要的内容。
到了第三代搜索引擎,就把链接清单给取消了,以搜索界面的形式展现搜索结果,也就是我们现在看到的大多数搜索引擎。
问题在于,在这个界面里,哪个搜索结果应该排在前面,哪个应该排在后面,这会直接影响到搜索结果的曝光度。
当时的各个搜索引擎,用过不同的逻辑去判断这个问题。
比如有一个早期的搜索引擎叫Direct Hit,排名机制主要靠搜索结果的用户点击率来决定。
在一开始,这种方法的确提高了用户看到优质搜索结果的可能性,Direct Hit也因此流行一时。
但是很快,就出现了利用机制漏洞刷点击率提高搜索位次的作弊者,搜索质量也随之大幅度下降。
这种情况其实和现在一些骗点击率的标题党,在逻辑上非常相似,只不过标题党更多的是针对推荐机制。
这是搜索引擎收获的第二个教训,并不是人多就代表正确。
其实排名机制本身是可以通过技术来达到一个比较好的效果的,比如Google就是通过大规模矩阵计算来判断网页价值和网页可信度的。
在这个时代的信息洪流下,Google每次检索排名都需要动辄完成十亿量级的矩阵计算,甚至一度陷入了计算力的瓶颈,最后还是用分布式计算的方法,解决了计算力的问题。
这些公司之所以用各种方法去调整搜索引擎的排名机制,固然是为了在竞争中占据优势,但是另一方面,也是因为排名机制的重要性。
不同的排名机制,会决定用户从搜索引擎上获取的信息,而信息的本质是思想。
思想的力量是很难衡量的。
搜索引擎在互联网上搜索出来的结果,以及搜索结果的排名,都可以直接影响到用户在现实中的决策。
某种意义上,搜索引擎是一个可以左右用户命运的产品。
03
我们常说技术没有价值观,这是对的,但不全对。因为很多面向人们刚需的技术,就是需要价值观来引导。尤其是搜索引擎,庞大的流量,是一座金矿。
1998年2月21日,后来改名为Overturn的搜索引擎GoTo想出了一个“天才”的操作。
它开始出售搜索结果排名,谁付的钱多,就可以指定谁排在前面。
这个决定让GoTo饱受非议,社会舆论的主要焦点就在于GoTo有没有充分的资质去审核那些愿意付费的机构甚至个人。
如果没有严格的准入机制,那么这不仅仅是打广告的问题,而会把搜索引擎变成一个只需要花钱就可以驱策的作恶工具。
在舆论的压力下,GoTo把Pay For Placement服务加上严格的重重限制。
道德初步赢了金钱。
当时的社会是普遍乐观的,认为搜索引擎以后会越发重视社会基本道德。
但是事情并不如人所愿,随着时间推移,这个付费排名后来还被发展为了更“天才”的竞价排名,彻底打开了潘多拉的魔盒。
其实现在的搜索引擎面临的问题,在搜索引擎发展的早期就已经有无数个死去了的搜索引擎产品踩过坑了。
太阳底下没有新鲜事。
作为一个能够大幅度影响人的产品,那么到底怎么使用,就非常考验价值观,企业在制定盈利策略的时候,是把用户当一个个活生生的人来看,还是仅仅把用户当可以变现的“流量”来看,会直接决定企业的所作所为。
微信搜一搜搞的“问医生”服务,去做提供责任到人的健康信息搜索,这些东西几乎没有经济效益,反而还要花大量的成本投入。
但是本质上,这不是一笔经济账。
在排除了一切利益考量后,去主动承担社会责任,这就是手握搜索引擎这种产品的公司,必须做出的选择。
其实,搜索引擎最合适的定位不是单纯作为一种盈利产品,而是作为优质内容矩阵的串联者,Google是这么做的,微信也是这么做的。
直接用搜索引擎变现,就和卖原材料一样,永远处在产业链的下游。
搜索引擎需要有社会责任感,流量也需要有更聪明的用法。
更何况在这个存量时代下,哪家的流量资源都不多。
谁能做好搜索引擎这个流量入口,谁就能灌溉好自己的一亩三分地,甚至去接济别人的水源。
04
搜索引擎的核心痛点是什么?是效率,没有其他。搜索引擎的迭代其实就是效率迭代。
世界上第一个web搜索引擎,是World wide Web Wanderer,只能搜集网址,没有跳转功能,你得自己知道网址,背下来,输进去,才行。
所以很快就被淘汰了。
往后出现的搜索引擎,一步步往便利的方向走。
先是ALIWEB增加了索引文件元信息的功能,也就是可以搜标题和标签了,接着第一个全文搜索引擎WebCrawler出现了,只需要输入全部文件内容中的一部分关键词,就可以获得整个文件信息,并且跳转到所在的网页。
对当时没几个人上网,网上也没多少内容的状况来说,这些原始的搜索引擎同样也够用了。
不光是Woeld wide Web Wanderer,包括早期的Yahoo!甚至都不是严格意义上的“搜索”引擎,而是人工编辑的网站目录,也就是第一代的搜索引擎,黄页模式。
当时Yahoo!成长得非常快,因为人工编辑可以保证信息质量,而只要人手忙得过来,其实对用户还是很方便的。
从搜索引擎早期的变化里,可以看出来,搜索引擎的原理本质其实是内容的分发。
后续的所有技术升级,都是因为互联网上的数据已经太庞大了,人工分发不过来,才需要技术来代替人工。但这是因为搜索引擎自身需要,而不是用户需要。
当用户数量少,内容基数小的时候,其实并不需要搜索引擎,或者说只需要穷举就好了。
早期的内容分发可以是非常粗略的,用户可以自己去浏览分类信息。
而当用户的需求和有可能满足这些需求的内容都达到了亿级,搜索引擎是不可能靠人工来分发这么庞大的信息量的,只有技术,才能把这些内容更高效地分发给需要的人。
而技术,有效率,但没有价值观。
如果只从信息的平均质量上来看,现在一个首页的前几条被竞价排名的搜索结果占据,后几条被摸清了搜索引擎算法的洗稿自媒体占领的搜索引擎,其实很可能还不如1994年的雅虎。
现在市场上主流的搜索引擎,在技术上其实都大同小异,原理上也没有差距。
在技术之外,为什么用户仍然会去选择不同的搜索引擎?搜索引擎未来的差异化竞争,到底应该差异在哪里?
答案还是效率。
搜索引擎的迭代,本质上是效率的迭代,是给用户带来的便利程度的不断突破。
很多人以为搜索引擎的软肋是广告,其实广告并不是核心问题。
没有广告,但是也找不到有用信息的搜索引擎,同样是不合格的。
搜索引擎真正的核心,在于帮助用户高效的解决问题。
而现在要进一步提高用户效率,帮助用户解决问题,需要的其实已经不是技术上的提升了,现在的技术已经够用了。
爬虫技术,数据储存技术,这些技术在当代都已经点到了溢出。
用户并不需要亿级别的信息全部呈现给他,而且事实上世面上任何一个搜索引擎,对互联网内容的抓取都不会超过30%,但是任何一个搜索引擎的主要问题都不会是搜到的信息不够多。
我们去搜索那些关键词的时候,我们真的需要几亿个结果吗?
我们真的会把搜索页面翻到几千页以后吗?
当然不会。
所以搜索引擎的下一个突破点也并不是技术。
不同搜索引擎的抓取内容本来也就不一样,两个主流搜索引擎之间至少有70%的抓取内容是不同的。在达到一定数量级后,信息的多少就已经并不重要。
因为在搜索引擎上,同一个宽泛的用户需求,永远有无数同位替代品。
大家需要的是,高效的,精准的,有用的东西。
只有和用户自身强相关的搜索,需要的结果才是确凿无疑、独一无二的。
这就是微信搜一搜的核心机会。
这个年代,比的反而是谁底子厚。
05
搜一搜好用,本质上是背后的数据壁垒深不见底。我写文章的时候经常会需要搜集资料,很多时候我要的不是一个有具体指向的结果,而是围绕关键词的一系列信息。这个时候信息质量非常重要。
不管用哪一家的搜索引擎,我都能搜到非常多的搜索结果,但是如果搜到的内容质量不高,我提炼起来就会非常痛苦。
我这里引入一个概念,“信息噪音”。搜索引擎给到你的一系列搜索结果里,绝大部分都是信息噪音,这种噪音是目前的技术很难解决的。
技术可以判断搜索结果和你的需求是否强相关,但是很难判断搜索结果的信息是否高质量。
一个最简单的例子,当搜索引擎去全网抓取信息的时候,你就不得不面临某些自媒体批量洗稿生产出来的“信息噪音”。
这些东西可能都出自同一个和你的需求强相关的内容,但是在被洗了几百次以后,如果它们还拥挤在搜索引擎给到的结果页上,就只能浪费用户的时间和生命。
对于那些强相关但是质量不过关的内容,目前只有具有一定知识水平甚至审美水平的人工审查才能分辨。
早期的搜索引擎,就是通过网站的编辑,对搜索结果一条条人工复审来降噪。
但是在这个时代,没有任何一个搜索引擎能够雇佣这么多人来排查所有抓取的数据。
所以我写文章的时候,都是用微信自带的搜一搜来查资料。这个时候搜一搜的内容来源,就成为了一个非常核心的优势。
它的资源主要来源于公众号。
每一个微信公众号的创作者,都相当于早期搜索引擎的人工编辑,在用他们的整合能力甚至创作能力,为搜一搜这个搜索引擎源源不断地提供高质量的、而且在实时更新的可抓取资源。
为什么说搜一搜是搜索引擎plus,除了之前讲到的在用户中心层面上的突破,就在于搜一搜的搜索结果都是已经经过了人为筛选过的。
并且筛选者的水平不差。无论是公众号还是知乎,都是中文领域最高质量的内容聚合。微信公众号体系特有的原创标识,更是甩开批量洗稿几百米,我搜出来的每一个结果背后,都可能是一群文字专家的心血。
在这种模式下,搜一搜获取高质量信息的频率和概率,都远超纯粹技术驱动的搜索引擎。
因为在这个搜索引擎的入口背后,是微信建立起来的庞大的内容生态。
尤其是搜一搜的内容来源,其实是半开放式的。搜一搜一直在引入新的靠谱的平台,现在不但可以搜微信公众号文章,还接入了像知乎这样的外部信息源。在不同的专业领域,也都在寻找该领域最专业的内容供应平台进行合作。
比如在健康领域,就接入了腾讯医典和企鹅医生,比起那些一搜关键词就把用户链接到几百个不同的小医疗信息平台的搜索引擎,搜一搜明显是一个内容来源“出圈”,并且内容更优化、质量更可信的信息搜索来源。
搜一搜背后的3000万公众号资源,以及整个知乎沉淀下来的深度内容,这些资源已经足够丰富了。
或许它们没有去全网抓取信息的搜索引擎那么丰富,但是用户搜索的目的本身也不是要丰富,他们要的应该是精准,深度,有效地解决问题。
比起广撒网,在互联网这片信息之海中,搜索引擎更需要修炼的,是点对点捕鱼的能力,这个能力背后,是数据储备。
这才是搜索引擎在第四个时代里,真正的核心竞争力。
或者说得再直白一点,搜一搜好用,本质上在于微信,在于这个有十一亿用户,已经聚合了N种生活服务,并且还可以通过搭载小程序来完成几乎任何服务的,一个庞大而不断自完善的生态。
搜索引擎单独拿出来不是大杀器,搜索引擎带来的存量资源激活才是。
06
所以发现了么?为什么微信要在这个时候开始发力搜一搜?随着存量市场的竞争进一步激烈化,搜索引擎的重要性也会进一步凸显。存量市场下,谁能激活自己的存量资源,谁就能赢。
还在用增量市场思维模式烧钱的企业,要死。
把搜索引擎做好的目的,不是用搜索引擎赚钱,而是为整个商业模式和存量资源做好服务。
这是真正属于大公司的战场,考验的绝不仅是搜索引擎本身。
而是搜索引擎背后的东西。
各家近期都在发力搜索引擎的背后,也是基于这样的逻辑。
阿里的夸克,头条的搜索,再加上微信的搜一搜。
新格局,要开始了。
作者:半佛仙人;作者公众号:半佛仙人(ID:banfoSB)
来源:https://mp.weixin.qq.com/s/xgb3DWw6GQ3B5Dm1DvjTqA
本文由 @半佛仙人 授权发布于人人都是产品经理,未经许可,禁止转载
题图来自 Unsplash,基于 CC0 协议