








智东西
编译 | 周炎
编辑 | 云鹏
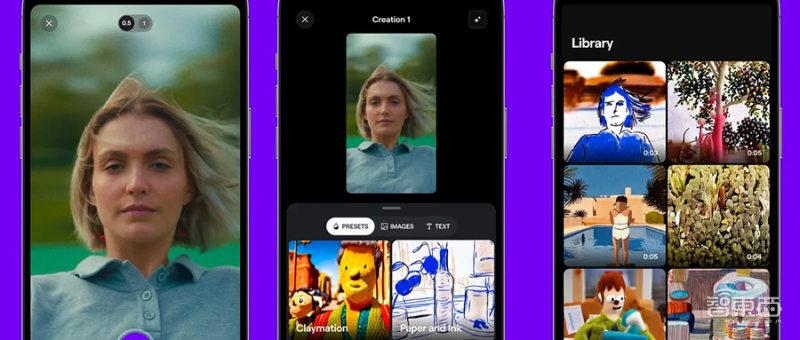
智东西4月26日消息,据The Verge报道,AI初创公司Runway近期在手机上推出了其第一款移动应用程序RunwayML,用户可以在自己手机上制作出各种风格的AI视频。据悉,这款应用程序使用了Runway此前推出的Gen-1模型,这是一种视频到视频(video-to-video)的生成式AI模型。当用户在应用程序中输入文本、图片、视频后,Gen-1模型可以根据用户输入的内容转化成对应的视频风格。
目前RunwayML中预设了六种图像风格,包括泥塑(Claymation)、折纸(Paper Origami)、水彩(Watercolor)、纸墨(Paper and ink)、素描(Charcoal Sketch)。当用户在这个应用程序中上传一段某人在公园骑自行车的视频后,可以选择“水彩”“素描”等指令作为输入,让视频变为不同风格。

The Verge称,这种功能类似于滤镜,但与滤镜不同的是,它不仅仅是简单地改变视频的颜色和质感。以上图展示的折纸风格为例,RunwayML会尽可能地识别用户所上传视频画面中的物品,并把所有物品都变成统一风格,例如在折纸世界里,原本画面中的人会变成纸片人。
今年3月,微软和IBM推出AI制图工具Midjourney,用户只需输入关键字,就可通过算法生成相应的图片。用户还可以选择不同画家的艺术风格,同时有别于谷歌的Imagen和OpenAI的DALL.E,Midjourney是第一个快速生成AI制图并开放给予大众申请使用的平台。作为只需要输入关键字、图片、视频等就可生成视频的RunwayML可谓是“视频领域的Midjourney”。目前,用户可以在App Store中免费下载RunwayML,但是每个月只有一定数量的免费额度。
需要注意的是,目前RunwayML的输出结果并非完美。例如,当用户在应用程序中输入“泥塑”的指令后,最终应用程序输出具有3D泥塑动画效果的视频可能并不让用户满意。视频中的物体会出现变形、变模糊等问题。
The Verge记者还亲身体验这款软件,他使用影片《热天午后》(Heat)中抢劫犯桑尼的代表性片段生成了三段不同的视频。右下角这个“穿西服的猫”就是在应用程序中输入一张猫的照片后生成的,可以看到该应用程序将猫的脸应用在桑尼的脸上,甚至还给桑尼的手上增加了毛皮,但同时也为桑尼保留了他的西装。

下图右侧这个纸墨版伦敦圣保罗大教堂(St.Paul’s Cathedral)生成也十分简单,用户只需在应用程序中输入“纸墨”的文字提示,伦敦圣保罗大教堂就变换了新风格。该记者称,一个有创造力的人使用这款应用程序,将会生成很多很有意思且特别壮观的视频。

Runway的CEO Crist ó bal Valenzuela称,让生成式AI工具在手机上使用是非常重要的,“因为你可以直接使用手机来录制视频,然后通过输入相关指令来让Gen-1模型转换成新视频。”
目前,Runway在手机上应用还有一些限制。例如,用户不能上传的视频时长不能超过5秒,同时用户也不能使用一些被禁止的输入提示。具体来说,用户不能不能生成裸体或版权受保护的作品等。The Verge记者在该应用程序中输入“吉卜力工作室风格”(in the style of a Studio Ghibli film)的提示,被应用程序所拒绝。据悉,“吉卜力工作室”是宫崎骏曾经所在的工作室,“吉卜力工作室风格”是日本动画的代表性风格。
在生成速度上,该应用程序生成每个视频大约需要2到3分钟,这个时间可能随着技术进步而缩短。目前,这个应用程序使用的是Gen-1模型,但Valenzuela称,更加先进的Gen-2模型很快也会用在该应用程序上。
目前来看,这种生成式AI工具虽然还有不成熟之处,但是却展示了视频生成领域的无限可能性。Valenzuela将当前的生成式AI比作为19世纪的“光学器具”(optical toys),它们虽然功能有限,但却是现代摄影机器的祖先。
结语:生成式AI在视频领域发展前景广阔
事实上,近期不止Runway一家公司在AI视频生成领域布局,英伟达最近也推出了AI视频生成模型VideoLDM,这款模型是与康奈尔大学相关团队合作打造的,VideoLDM共有41亿个参数,其中27 亿个经过视频训练,这符合现代生成式AI的标准。此前,谷歌推出Imagen,OpenAI推出DALL.E,也都显示出行业巨头对AI视频生成领域的重视。
今年2月,Gartner发表预测称,到2030年,电影大片中AI生成内容的比例(从文本到视频)将从2022年的0%上升到90%。可以预见的是,生成式AI未来将会更广泛地应用于视频领域。
来源:The Verge